

Intuitive.Computer @Intuitive_Comp
Machine that thinks like you, and explains why. intuitive.computer Joined February 2026-
Tweets3
-
Followers0
-
Following38
-
Likes0
New Science Blog: Why has AI advanced faster in coding than in biology? To agents, bio databases are like cities built before cars—maddening to drive in because they're designed for different traffic. How do we build infrastructure agents can use? anthropic.com/research/agent…
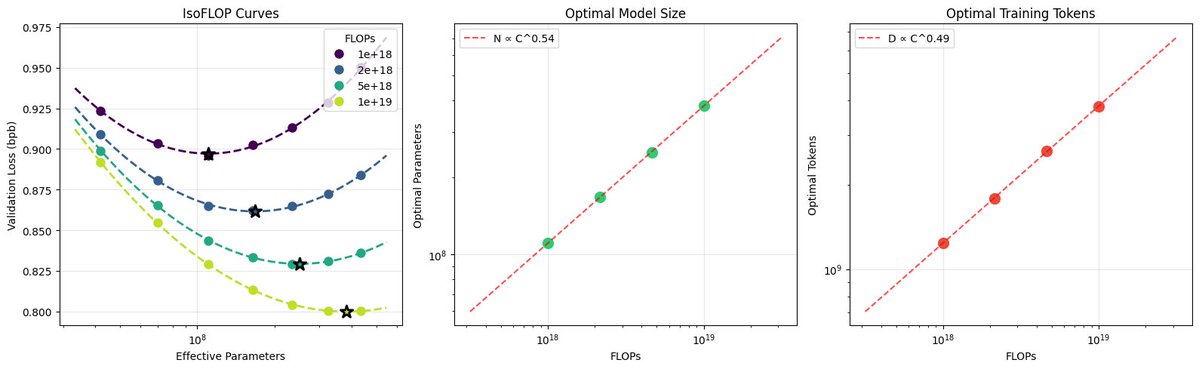
nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node). GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train a model to GPT-2 capability but for much cheaper, with the benefit of ~7 years of progress. In particular, I suspected it should be possible today to train one for <<$100. Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc. As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year. I think this is likely an underestimate because I am still finding more improvements relatively regularly and I have a backlog of more ideas to try. A longer post with a lot of the detail of the optimizations involved and pointers on how to reproduce are here: github.com/karpathy/nanoc… Inspired by modded-nanogpt, I also created a leaderboard for "time to GPT-2", where this first "Jan29" model is entry #1 at 3.04 hours. It will be fun to iterate on this further and I welcome help! My hope is that nanochat can grow to become a very nice/clean and tuned experimental LLM harness for prototyping ideas, for having fun, and ofc for learning. The biggest improvements of things that worked out of the box and simply produced gains right away were 1) Flash Attention 3 kernels (faster, and allows window_size kwarg to get alternating attention patterns), Muon optimizer (I tried for ~1 day to delete it and only use AdamW and I couldn't), residual pathways and skip connections gated by learnable scalars, and value embeddings. There were many other smaller things that stack up. Image: semi-related eye candy of deriving the scaling laws for the current nanochat model miniseries, pretty and satisfying!

tphuang @tphuang
35K Followers 401 Following My random thoughts on EVs, clean energy, chips, aerospace and other tech. Find more extended pieces at substack https://t.co/Jmo8iyjHrn
Joe Lowry @globallithium
32K Followers 300 Following Global Lithium™ provides advisory services to the lithium-ion battery supply chain with clients on 5 continents. Host of The Global Lithium Podcast and author.
Sxcoal @sxcoal
8K Followers 949 Following China and intl coal market news, analysis, prices, statistics, and reports. Sxcoal app: https://t.co/HNk9JRmeH5 WA Channel: https://t.co/np0xFA6ttu
Teo @Teo_Sinamin
8K Followers 83 Following I help mining companies avoid costly mistakes in China-facing deals. Covering critical minerals - tungsten, rare earths, export controls - from the inside.
Bessemer @BessemerVP
138K Followers 1K Following For the entrepreneurs who want to build revolutions of their own.
Paulo Macro @PauloMacro
193K Followers 370 Following Speculation is the search for truth in price and time. Not investment advice - just personal views. Blog at https://t.co/DD2iUKbdLz

Dr. Pat Soon-Shiong @DrPatrick
156K Followers 2K Following Chairman of Chan Soon-Shiong Family Foundation, Exec Chairman ImmunityBio, Chairman and Chief Executive Officer of Los Angeles Times Media Group (LATMG)
Astera Institute @AsteraInstitute
10K Followers 29 Following We empower visionary, high-leverage science and technology projects with the capacity to create transformative progress for human civilization.

Michael West @GerontologyMike
1K Followers 12 Following To understand human aging and craft a means of intervention in it is the greatest calling of mankind. How we meet that challenge will define us as a species.
Claire Burch @claireburch_
188 Followers 430 Following @Contrary_Res // formerly @Harvard @Bridgewater
Life Biosciences @lifebiosciences
23K Followers 235 Following Rejuvenating cells to reverse age-related diseases.
GenScript @GenScript
9K Followers 1K Following Committed to striving towards the vision of being the most reliable biotech company in the world to make humans and nature healthier through biotechnology.
Ed Zitron @edzitron
126K Followers 6K Following Newsletter https://t.co/D5qDgUKaNR - Better Offline Podcast - https://t.co/pUoGsuaQTw - CEO at https://t.co/5idt8AyPqr
ClaudeDevs @ClaudeDevs
523K Followers 2 Following Official updates for developers building with @ClaudeAI

Roan @RohOnChain
51K Followers 676 Following building my life around quant systems in prediction markets and crypto
Anthropic @AnthropicAI
1.4M Followers 2 Following We're an AI safety and research company that builds reliable, interpretable, and steerable AI systems. Talk to our AI assistant @claudeai on https://t.co/FhDI3KQh0n.

Contrary Research @Contrary_Res
15K Followers 130 Following The best starting point for understanding private tech companies. Powered by @contrary. Subscribe to our newsletter below:
Yi Ma @YiMaTweets
120K Followers 716 Following Chair Professor in AI, Hong Kong University. A Mathematical Theory of Intelligence/Memory: https://t.co/leZlkURb7j
LeRobot @LeRobotHF
17K Followers 25 Following ~ Lowering the barrier to entry for robotics ~ Crafted with care by @HuggingFace 🤗 Join our discord: https://t.co/Sx2jdT0jeF
AscentagePharma @AscentagePharma
64 Followers 6 Following
Matt Schwartz @matt_is_nice
2K Followers 3K Following CEO/founder of Virgo. Building frontier AI to solve gut-mediated diseases like colorectal cancer, pancreatic cancer, IBD, and more
Peter Ottsjö @peterottsjo
4K Followers 2K Following Journalist covering biotech & AI (➡️ https://t.co/XGxbqDfhBa), longevity (➡️ https://t.co/z7HYGJGlzh or @reachlevity). Reporter at Swedish tech outlet @nyteknik.
SemiAnalysis @SemiAnalysis_
110K Followers 27 Following
Winston @ChurchillWw
3K Followers 333 Following Manufacturing, energy, trade, infrastructure. 25+ years operations/sales/finance. [email protected] https://t.co/NkwD2u1NcK
Grant Stenger (hiring... @GrantStenger
14K Followers 6K Following Kinetic CEO | prev @janestreetgroup @polychain @numerai
NonsparseOncologist @5_utr
3K Followers 380 Following Oncologist | RadOnc | Stats #Rstats | Opinion | Politics | Never Trump
Robert Timmerman @BobTimmermanMD
4K Followers 74 Following Chair of the Department of Radiation Oncology at UT Southwestern Medical Center. Views are my own.
Legend Biotech @LegendBiotech
1K Followers 303 Following We are a global #celltherapy company focused on developing, manufacturing and commercializing #cancer treatments. $LEGN
Legend Biotech Medica... @LegendUSMA
135 Followers 314 Following We provide medical & scientific updates from Legend Biotech. Intended for US HCPs only. See pinned post for inquiries and community guidelines.
Ethan Mollick @emollick
362K Followers 586 Following Professor @Wharton studying AI, innovation & startups. Democratizing education using tech Book: https://t.co/CSmipbJ2jV Substack: https://t.co/UIBhxu4bgq

Yann LeCun @ylecun
1.2M Followers 787 Following Professor at NYU & Executive Chairman at AMI Labs. Ex-Chief AI Scientist at Meta. Researcher in AI, Machine Learning, Robotics, etc. ACM Turing Award Laureate.
SpaceX @SpaceX
41.9M Followers 123 Following SpaceX designs, manufactures and launches the world’s most advanced rockets and spacecraft
You might like



















