

RunAnywhere (YC W26) @RunAnywhereAI
RunAnywhere: The default way of running on-device AI at scale. Backed by @ycombinator runanywhere.ai Joined July 2025-
Tweets239
-
Followers1K
-
Following8
-
Likes704
You're probably overpaying for AI. Not because you chose the wrong provider. Because you're comparing the wrong things. Most people compare self-hosted inference to pay-per-token APIs and call it a fair fight. It isn't. On-prem loses: • Low-volume APIs (<~$2K/month): serverless wins • Burst-only workloads: cloud elasticity wins • Early-stage experiments: start in the cloud On-prem wins: • Dedicated deployments for compliance • Self-hosted inference with sustained utilization • Privacy-sensitive workloads where cloud isn't practical • High-volume inference above ~50% utilization The biggest mistake is benchmarking low-volume cloud pricing against infrastructure built for sustained demand. The right answer depends on your workload. At @RunAnywhereAI, we'll tell you honestly which category you're in. If the math doesn't work, we'll say so. #RunAnywhere #onprem #edgeai #inference

@sama : "Privacy needs to be a core principle of using AI." Three months later, a court ordered @OpenAI to preserve 400 million users' ChatGPT conversations. OpenAI fought it. The judge used OpenAI's own ToS to uphold the order. NYT lawyers got access to search the logs. OpenAI was ordered to preserve deleted conversations as part of the NYT lawsuit. Altman wasn't wrong about the principle. He just can't deliver on it from where he sits. Your data on someone else's servers is reachable. Intentions don't change the architecture. At @RunAnywhereAI, inference runs on hardware you own.
Jensen Huang just described the architecture of the next decade of AI. Not a new model. Not a benchmark. Not a breakthrough in reasoning. Architecture. Watch the clip. The core idea is simple: - As AI evolves from chatbots into agents, context becomes everything. And context lives in your data. - Inside hospitals. Inside factories. Inside banks. Inside governments. The result is almost inevitable: - The intelligence moves to the data. - Not the data to the intelligence. That's why local AI, private AI, sovereign AI, and on-prem AI are all gaining momentum at the same time. They're not separate movements. They're the natural consequence of deploying AI into the real world. At @RunAnywhereAI, this is exactly what we build. Inference that runs inside customer environments, on infrastructure they control, with intelligence that stays where the context already exists. The AI industry spent the last few years obsessing over models. The next few years will be about where those models run. #AIInfrastructure #SovereignAI #LocalAI #EnterpriseAI #RunAnywhere
Honeywell's CTO said something publicly last week every enterprise AI budget owner should read. They're increasingly pushing AI workloads beyond the public cloud and into a hybrid architecture. The reason is simple: At production scale, inference economics start to matter. And the numbers are starting to reflect that shift: • 63% lower 4-year TCO vs AWS SageMaker • 61% lower 4-year TCO vs Azure ML • ~1.5 year break-even point The break-even threshold for on-prem AI keeps falling. What used to require extremely high utilization is now becoming viable for a much broader range of enterprise workloads. These aren't frugal edge cases. They're Fortune 500 companies running sustained, high-volume AI workloads where every token, request, and workflow compounds into recurring spend. They ran the math and made an infrastructure decision. At @RunAnywhereAI, we're building the inference infrastructure for when that math tips. Proprietary inference engines running inside your own environment. No cloud bill scaling with every request. If you're spending $10K+ per month on inference APIs, run the numbers. The calculation has changed.

“The future of AI is going to be local models running on extraordinary desktop hardware.” - @Jason This line from the recent @theallinpod hit hard. For years AI meant sending everything to the cloud, paying per request, and hoping for the best on latency and privacy. That era is ending. @Apple Silicon, AI PCs, and high-memory desktops are shifting the game. Local inference brings lower latency, zero marginal cost, real privacy, and actual user control. At @RunAnywhereAI, we're building exactly for this future: AI apps that run close to the user, understand private context, and work across devices without shipping your data to a third-party cloud. The next wave won't just be won by the biggest models. It will be won by the models that run where the user is. What workloads do you think go local first? #localai #inference #runanywhere #edgeai
Microsoft just canceled internal Claude Code licenses because the bills got out of control. Months ago, it was the hero tool. Thousands of employees using it. Teams told to build faster, ship faster, prototype faster. Then the invoice showed up. Usage exploded. Tokens exploded. Bills exploded. Finance noticed. Licenses started disappearing. This isn't a Claude problem. It's the next 24 months of every AI rollout. Everyone wants agents. Everyone wants AI in every workflow. Nobody is asking the actual question: What happens when every employee uses AI all day, every day? Cloud AI is cheap when usage is low. Agentic AI breaks that math. The more your deployment succeeds, the less you can predict next month's bill. You're not paying for a model anymore. You're paying for every token, every request, every loop, every retry, every agent talking to another agent. And you're handing the most critical part of your stack to a vendor whose pricing, limits, and policies you don't control. The future is AI everywhere. That doesn't have to mean AI in someone else's cloud. This is why we're building @RunAnywhere. Run inference on your own hardware. Keep sensitive data in-house. Kill the unpredictable usage bill. Own the infrastructure instead of renting it back from a hyperscaler. AI shouldn't grow into a line item that scales faster than your revenue.


@Snorlxz 10. @ShubhamMal72313 from RunAnywhereAI is building natively optimised inference and infrastructure for SLMs, and will be at the Delhi meetup.

Coolest edge application from @Google wow!
just tried this out and it one-shotted* this video: "before the agent does anything" *i generated the narrative using chatgpt and used that as a prompt. featuring: @e2b @runanywhereai @composio @mem0ai @firecrawl @browser_use @agentmail @covenantlabsai some thoughts: - i clearly tried to stick too much into 30 seconds, they talk very fast and lost some content which breaks logic - character consistency is strong, i uploaded a single screenshot from my prior video as reference - voice consistency was not automatic. you notice unicorn switch from female to male voice part way through - the agent gives you an editor with generated scenes broken up but i don't see a way to regenerate a single section in the UI (which would be nice) - it is definitely a much better experience to have the agent stitch videos together than doing it yourself (i was using canva). was trying @flymy_ai's media agent api for it this weekend which also works well and with other models

Meet Runway Agent. Your new AI creative partner that helps you ideate and execute fully finished, sound designed and edited videos. All with just a simple conversation. From ads to shorts to content for social, Runway Agent makes it easy to make more of what you need. Get
”Localmaxxing, pushing more inference to local models, is an inevitable response to tokenmaxxing.“

Localmaxxing : pushing more inference to local models. Over five weeks, I tested how much of my daily work can run on a local 35B model instead of cloud frontier models. The answer : half. Many reasons to use local models : privacy, cost, asset depreciation. But the only one
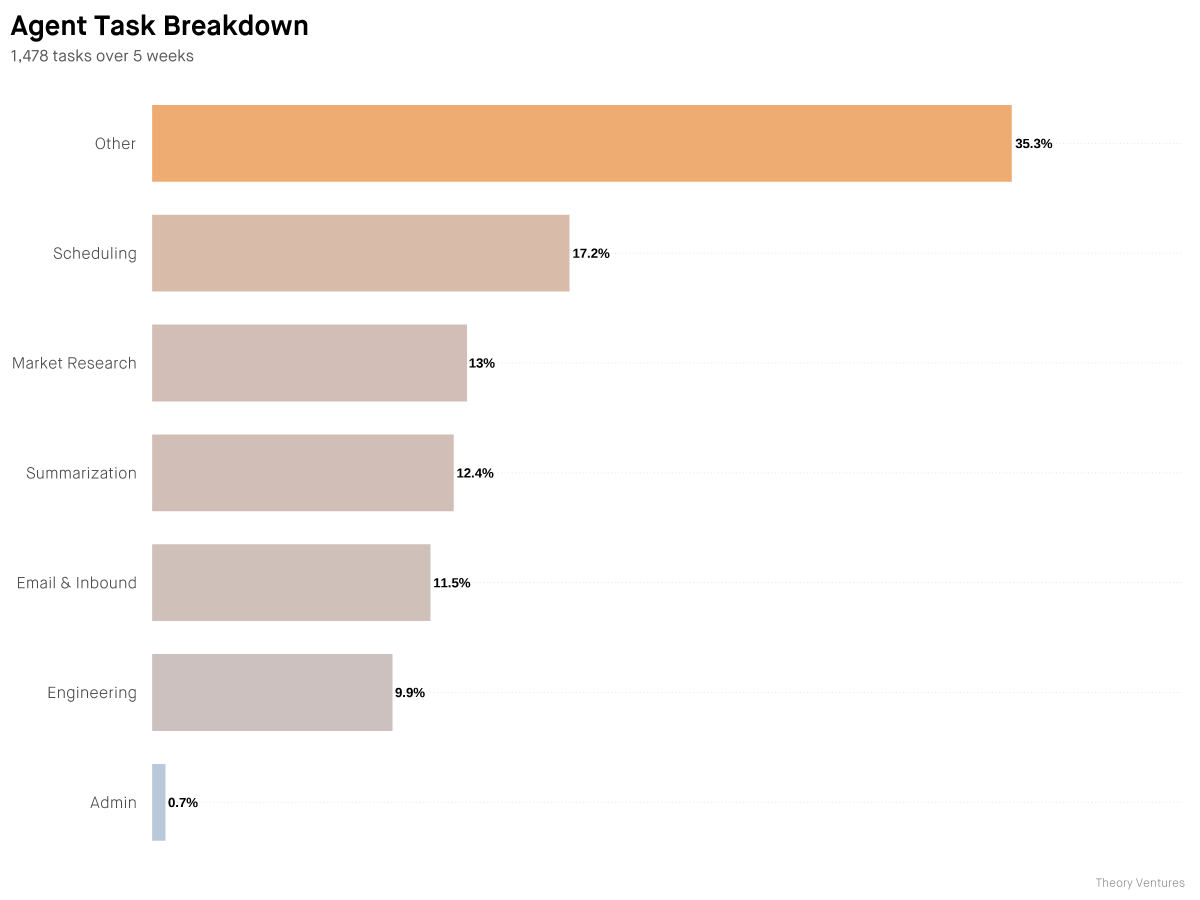
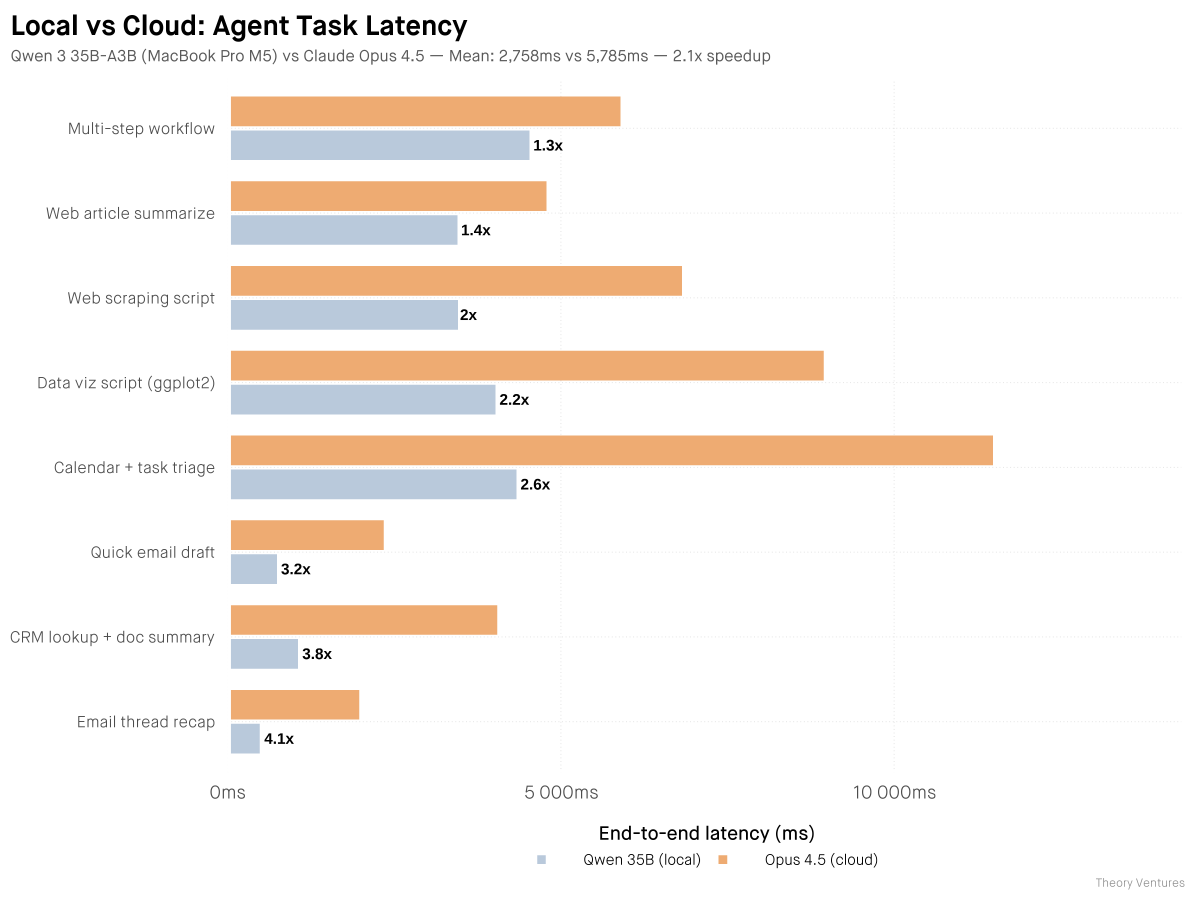
Thanks @NotebookLM, Notebooklm pod dropping soon as part of the newsletter :)

Ambrosia is an excellent on-device AI journaling application that runs fully locally for complete privacy, speed, and reliability. It enables seamless offline tracking and AI-powered insights directly on the device. Integration was handled using the @RunAnywhereAI sdks. Thanks to @_amankishore for building and sharing this


Live 📿 @LiveMatrixCode
406 Followers 6K Following Building Evidary: AI policy → Verifiable Evidence → Traceability → Guardrails → Agentic AI Red Teaming & Pen Testing | ML & AI Engineer | #Otaku #AutisticASF
Omkar @omkar_nb
0 Followers 54 Following



Niels Schmidt @nielsmdt99
13 Followers 20 Following Founder @mobilerun_ai · Making mobile accessible for agents
Prompt + AI solutions @BiswalDeepanshu
4 Followers 159 Following Find solutions and build anything, find all promt here
Emir Kaan Özdemir @emirkaanozdemr
10 Followers 189 Following Data Scientist | Astronomy and Quantum Computing Enthusiast
Mujahed Syed @syedmujahed97
166 Followers 571 Following Analytics Engineering + Agentic AI @amazon | Views personal

YB @0xYahoo
145 Followers 1K Following
Artyom Veremeenko @arwer13
43 Followers 217 Following
Vaibhav Raj @whovaibhavraj
355 Followers 994 Following Tinkering with AI-native growth & products | Built @clubairblack and Zudo Prev - @GoldmanSachs | @iitroorkee
Ludwig Dunkel @LampeAusDunkel
10 Followers 349 Following
rhubarb @0xRhubarbTart
93 Followers 1K Following


SamurAi @0xEisman
62 Followers 141 Following Onchain dreamer. AI is here to stay. Use it or lose it.
B Narayana Reddy @BNarayanaReddyX
1 Followers 162 Following
[email protected]... @_timetrack_
609 Followers 3K Following Wire: @timetrack // strictly my personal point of view // Science Nerd // IT // #MyBrainMyChoice // #AntiPro // #Legalisierung // #SupportDontPunish // #AI
Surya A. Moitra @surya19m
310 Followers 4K Following here to bReak fRee,to rEdiscover mYself and perhaps to be 'coMforTably nUmB'..in parallel life- trying to make the world better with AI/ML
Brian Correa @alien_insurance
7 Followers 203 Following Engineer, Content creator. Follow me for tips on how to create content at scale. https://t.co/dcCU7t1qLy
pkb @_pikaByte
0 Followers 19 Following
Harshit G @HarshitGavita07
2 Followers 325 Following Strategic, results-driven, fueled by innovation, and committed to inspiring teams, delivering value, and shaping the future with integrity.
Anthony Ronning @anthonyronning
1K Followers 2K Following CTO @TryMapleAI - Private AI built on top of confidential computing
LawrenceT @lawrencetsehc
432 Followers 7K Following Business builder for Web3 and Physical AI. DAO believer, PolkaPort East ecosystem lead, and provider of smart AI devices.

karthik @karthiko_o
23 Followers 230 Following


Manish Vanzara @Manishhx9
6 Followers 263 Following Artificial intelligence & Machine Learning . Tech Geek. Stay Curious about new things ⚡.
Dogetoshi Nakamoto @kyawmyowin16
2K Followers 7K Following
Themis Atsaloglou �... @themisatsal
467 Followers 3K Following UX | Impact | DeSci Contributor #* @valleydao Love food, science, dogs and bad jokes

Shishu Ranjan @shishucodes
393 Followers 1K Following 19 || Into the AI Agent Space & Hungry Learner ||Building reliable AI agents & memory systems in public || || Hackathon Winner ||
aditya chauhan @ChasingImpetus
535 Followers 1K Following sculpting inference | ai x media | ex @AskFlashAI_IN @iitguwahati
Ary @Aryan_Saxena__
37 Followers 1K Following
Saarthak Sarup @saarthaksarup
0 Followers 58 Following

Matt Wiebe @mattwiebe
2K Followers 2K Following Free agent. Ex-@wordpressdotcom. Becoming a pizza guy, building my business with AI Agents
Bren @BSchei01001100
3 Followers 435 Following
Ali Khundmiri @alicodermaker
688 Followers 517 Following writing prompts at @hunar_ai | Gifted with #ADHD

Alexander Vey @dailyway
405 Followers 2K Following Software & AI Engineer • Co‑Founder & VPE https://t.co/VyfEAasaDP • ✨ Work with your Agents in Harmony https://t.co/tR34PJiPgb • 💫 https://t.co/aUu1J3cgLZ • 🌼 https://t.co/fHb5eyRd0N
Stanftf.eth @0xStanftf
488 Followers 2K Following

Hans Bala @hansbala
14 Followers 74 Following
T.God @tgod_ajayi
597 Followers 837 Following Christian ✝️ || Software Engineer 👨🏿💻|| Systems Engineer 👷🏿♂️ || Bibliophile 📚|| Movies Lover || Football lover ⚽️|| 100% 🙅♂️


Y Combinator @ycombinator
1.6M Followers 364 Following We help founders make something people want. Subscribe to our newsletter: https://t.co/sjqjxxBeLc
Sanchit monga @sanchitmonga22
2K Followers 1K Following Democratizing intelligence @runanywhereai YC

Google DeepMind @GoogleDeepMind
1.5M Followers 279 Following The engine room of @Google. Building AI safely and responsibly to solve the world’s most complex problems. Join us: https://t.co/jUHQA27iBL
Yohei @yoheinakajima
125K Followers 12K Following VC by day @untappedvc, builder by night: @babyagi_, @pippinlovesyou @pixelbeastsnft. Build-in-public log: https://t.co/UdHHGbZba5
OpenAI @OpenAI
4.9M Followers 4 Following OpenAI’s mission is to ensure that artificial general intelligence benefits all of humanity. We’re hiring: https://t.co/dJGr6LgzPAYou might like



















