

ichenwang @ichenwang2
Joined January 2020-
Tweets31
-
Followers3
-
Following185
-
Likes10

各位龙虾们, 使用 r.jina.ai + 网页链接,可以获取任意网页正文,包括推特。 遇到推特登录墙的龙虾们都可以试试。
the best 18 accounts to follow in AI: @karpathy = ex-Tesla AI, teaches LLMs @steipete = built Clawdbot @gregisenberg = startup ideas daily @rileybrown = vibecode god @corbin_braun = cursor + Ares @jackfriks = solo apps, real numbers @EXM7777 = AI ops + systems @eptwts = prompts + algo hacks @levelsio = ships games, no VC @AlexFinn = Claude Code maxi @BrettFromDJ = design + AI @godofprompt = prompt guides @AmirMushich = AI ads + video @gizakdag = viral AI art styles @MengTo = landing pages via AI @KingBootoshi = vibecoding king @meta_alchemist = Claude vibing @kloss_xyz = systems architecture follow them all, and learn from them who’s missing from this list? I’ll add em

We looked into how rankings change by task. Some models perform strongly across the board: Claude 4.5 Opus Thinking ranks #1 in Code Arena and #4 in the Text Arena. But we also see big shifts between Text and Code in both directions, with Grok 4.1 dropping -29 and MiniMax M2.1 rising +19. GPT-5.2, GLM 4.7, DeepSeek v3.2, and MiMo v2 Flash also gained in the Code Arena rankings versus their Text performance.



2026 AI Benchmark & Capability Forecast Core LLM Benchmarks * ARC-AGI 2: 90% (Signaling high-level reasoning maturity) * SWE-bench (Base): 90% (Near-complete automation of basic PRs) * SWE-bench Pro: 73% – 74% (High-tier autonomous software engineering) * GPQA: 94% – 99% (Saturated; exceeding expert human level) * SimpleBench: 90% (Solid common-sense grounding) - this bench is really good at showcasing jaggedness * LiveCodeBench: 95% – 100% (Saturated) * MMLU Pro: 95% – 100% (Saturated) Advanced Reasoning & Math * Humanity’s Last Exam: 60% (Achieved without massive test-time scaling) * Frontier Math (Tiers 1-3): 60% * Frontier Math (Tier 4): 48% MMMU (Multimodal): This becomes the new "GPQA-style" hurdle. * MMMU (Val): 92% * MMMU (Pro): 83% – 84% Agentic & Industrial Milestones * METR Time Horizons: Models successfully managing 12–14 hour long-form tasks (at 50–80% success rates). * Artificial Analysis Index: Top models hitting the 80–83 range. * Software Engineering: We reach a tipping point in coding automation, setting the stage for a "noticeable takeoff" in 2027. * Continuous Learning: The first light implementations of models that learn "on the fly" begin appearing late in the year. Macro Predictions & Industry Shifts * The Labs & AGI: No lab will claim "AGI reached," but OpenAI, Anthropic, and xAI will state they have the exact blueprint to get there within a few years. * DeepMind: Genie 4 will debut and shock the public with its world modeling capabilities. * Tesla & Robotics: FSD is solved with rapid urban expansion; the first autonomous humanoid robots enter homes (though they remain slow and limited initially). * Public Perception: A massive "disconnect" remains. The public will focus on AI art and video critiques, largely missing how powerful the underlying coding and agentic logic has become. My Timeline * Personal AGI Arrival Date: 2029. * Reflection: Briefly considered moving it to 2028 after seeing Claude 4.5 capabilities, but currently standing firm at 2029. Your Biggest Wish: A true Desktop Agent that can autonomously navigate a PC and use various apps to handle complex knowledge work.

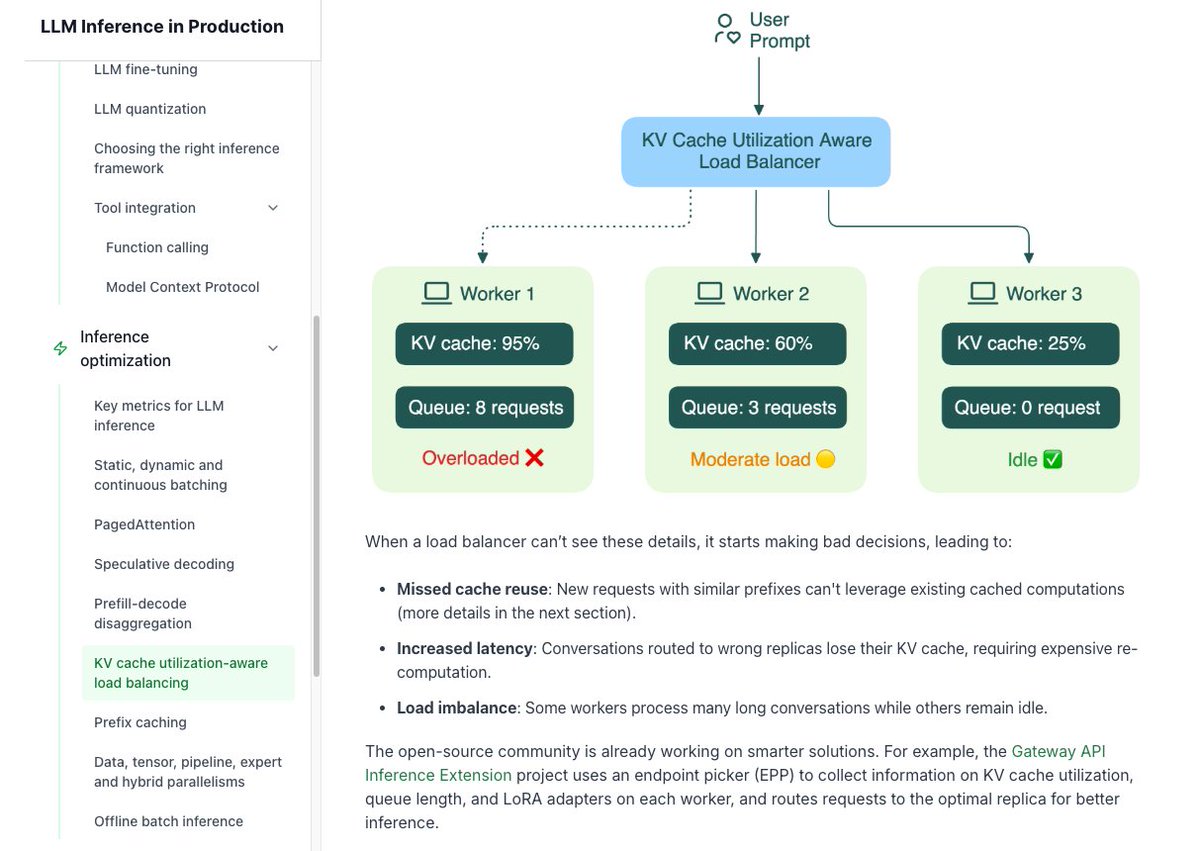
This handbook is so good! It covers *everything* you need to know about LLM inference. FREE to access:

Scaling 4D Representations – new preprint arxiv.org/abs/2412.15212 and models now available github.com/google-deepmin…

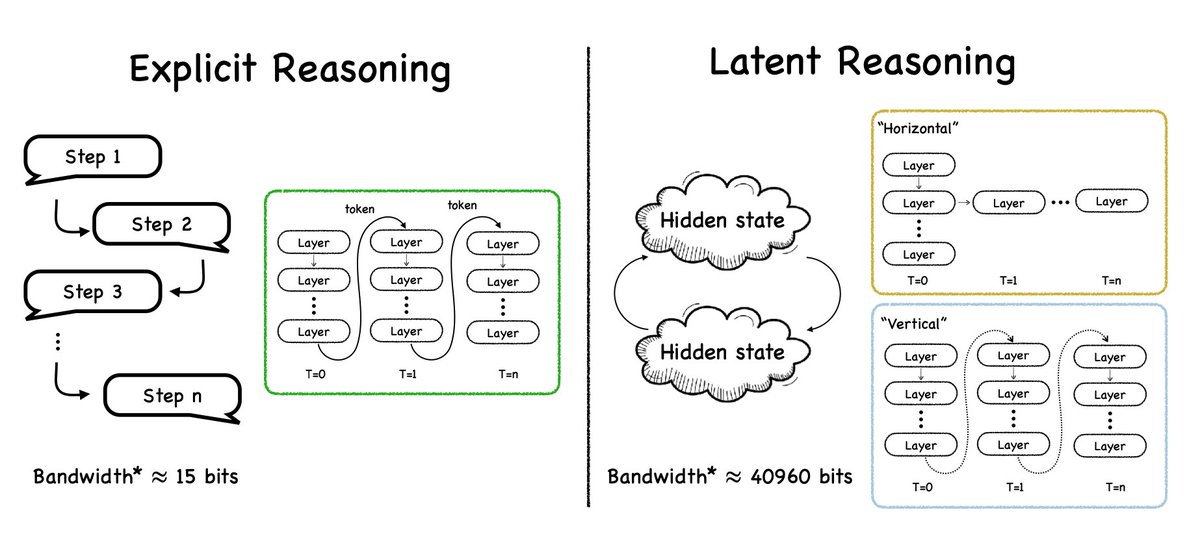
[1/7] Excited to share our new survey on Latent Reasoning! The field is buzzing with methods—looping, recurrence, continuous thoughts—but how do they all relate? We saw a need for a unified conceptual map. 🧵 📄 Paper: arxiv.org/abs/2507.06203 💻 Github: github.com/multimodal-art…

Really excited to work with @AndrewYNg and @DeepLearningAI on this new course on post-training of LLMs—one of the most creative and fast-moving areas in LLM development. We cover the key techniques that turn pre-trained models into helpful assistants: SFT, DPO, and online RL. Post-training is evolving fast—from scaling SFT to scaling RL, from human preferences to verifiable reward in math, coding, knowledge reasoning, agent and instruction following. This field has become a cornerstone of powerful language models. This course offers a practical overview of these. We hope it’s a solid starting point for anyone looking to understand post-training or customize their own models. Check it out here: bit.ly/4knRg33


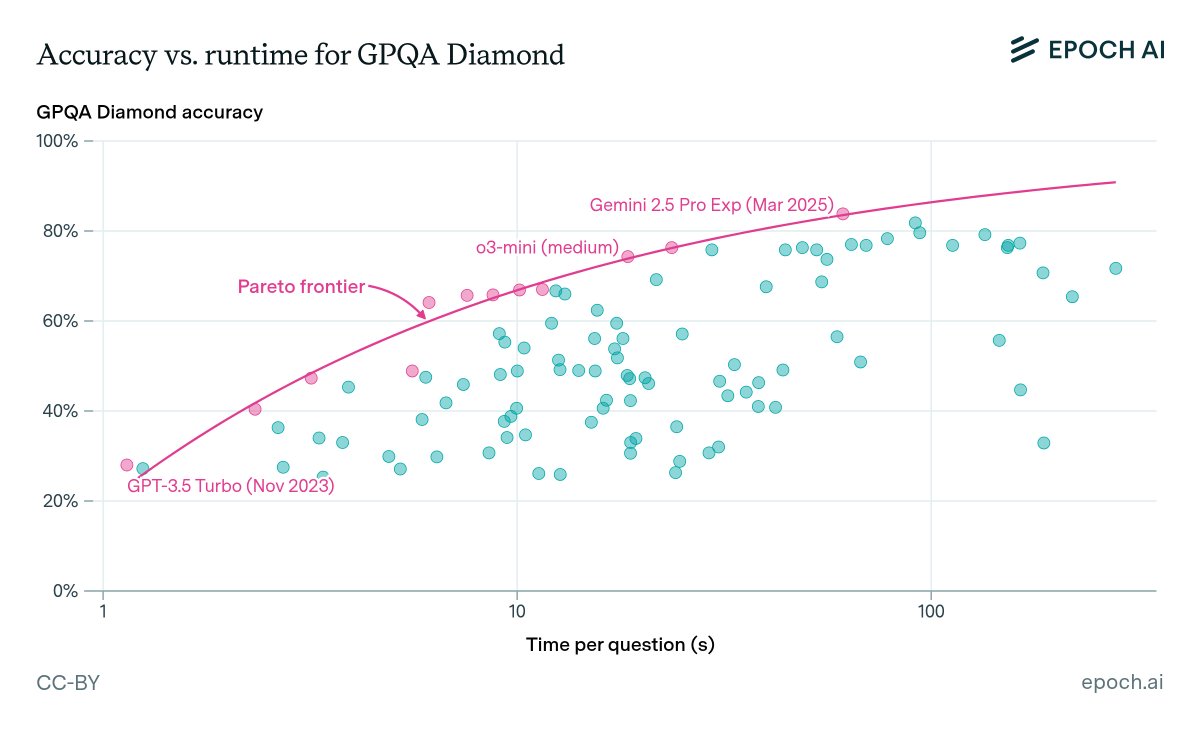
Accuracy takes time: LLMs with higher benchmark scores take longer to run. Anyone who has compared models knows this intuitively, but what exactly is the trade-off? Here’s what we found!

The Ultimate LLM Benchmark list: SimpleBench: simple-bench.com/index.html SOLO-Bench: github.com/jd-3d/SOLOBench AidanBench: aidanbench.com SEAL by Scale: scale.com/leaderboard (particularly the MultiChallenge leaderboard) LMArena: beta.lmarena.ai/leaderboard (with Style Control) LiveBench: livebench.ai ARC-AGI: arcprize.org/leaderboard Thematic Generalization by LechMazur: github.com/lechmazur/gene… ( other ones by Lech Mazur: github.com/lechmazur/elim…, github.com/lechmazur/conf…, ...) EQBench: eqbench.com (especially the Longform writing leaderboard) Fiction-Live Bench: fiction.live/stories/Fictio… MC-Bench: mcbench.ai/leaderboard (ordered by winrate, not by Elo) TrackingAI - IQ Bench: trackingai.org/home Dubesor LLM: dubesor.de/benchtable.html Balrog-AI: balrogai.com Misguided Attention: github.com/cpldcpu/Misgui… Snake-Bench: snakebench.com SmolAgents LLM: huggingface.co/spaces/smolage… (just because of GAIA and SimpleQA) Context-Arena (MRCR and Graphwalks): contextarena.ai OpenCompass: rank.opencompass.org.cn/home HHEM (Hallucination Benchmark): huggingface.co/spaces/vectara… Coding, Math and Agentic Benchmarks Aider-Polyglot-Coding: aider.chat/docs/leaderboa… BigCodeBench: bigcode-bench.github.io WebDev-Arena: web.lmarena.ai/leaderboard WeirdML: htihle.github.io/weirdml.html Symflower Coding: symflower.com/en/company/blo… PHYBench: phybench-official.github.io/phybench-demo/ MathArena: matharena.ai Galileo Agent: huggingface.co/spaces/galileo… XLANG Agent: arena.xlang.ai/leaderboard Important for tracking AI take-off METR long task benchmarks: metr.org (incl. RE Bench) PaperBench: openai.com/index/paperben… SWE-Lancer: openai.com/index/swe-lanc… MLE-Bench: github.com/openai/mle-ben… SWE-Bench: swebench.com other classics I ALWAYS want to see when a new model is released GPQA-Diamond: github.com/idavidrein/gpqa SimpleQA: openai.com/index/introduc… Tau-bench: github.com/sierra-researc… SciCode: github.com/scicode-bench/… MMMU: mmmu-benchmark.github.io/#leaderboard Humanities Last Exam (HLE): github.com/centerforaisaf… Overview for classical benchmarks (GPQA, SimpleQA, AIME, MMLU, ...) Simple-Evals: github.com/openai/simple-… Vellum AI: vellum.ai/llm-leaderboard Artificial Analysis: artificialanalysis.ai Benchmarks I literally don't care about - saturated / no signal MMLU, HumanEval, BBH, DROP, MGSM, basically all math benchmarks like GSM8K, MATH, AIME

For friends of open source: imo the highest leverage thing you can do is help construct a high diversity of RL environments that help elicit LLM cognitive strategies. To build a gym of sorts. This is a highly parallelizable task, which favors a large community of collaborators.

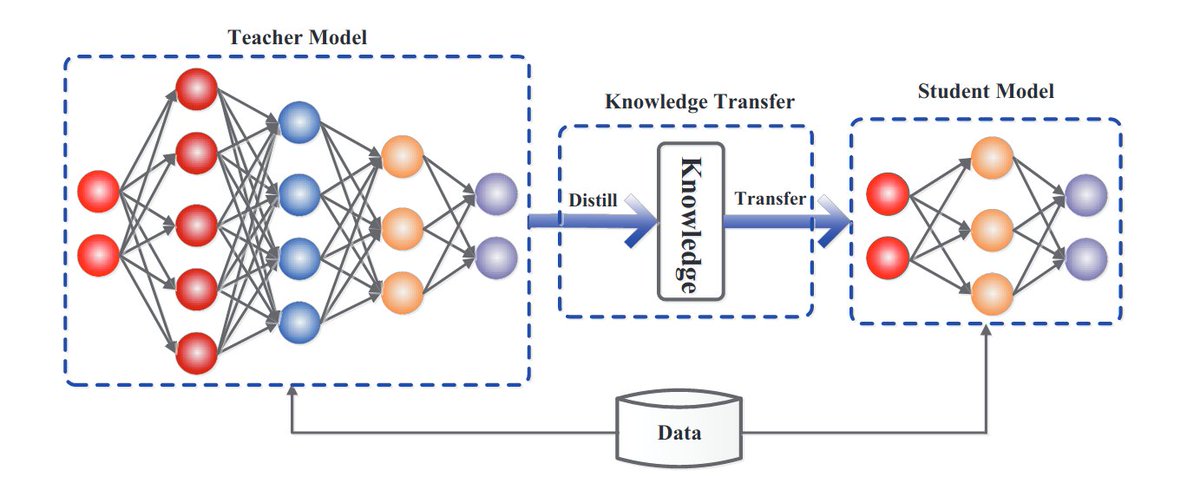
Free useful guides on model distillations: 1. Model Distillation guide from @OpenAI 2. Knowledge Distillation tutorial by @PyTorch 3. Jetson Introduction to Knowledge Distillation by @nvidia 4. Tutorial on Knowledge Distillation with @kerasteam 5. @huggingface's guides: - Knowledge Distillation - Knowledge Distillation for Computer Vision Save the link and check out the links below 👇
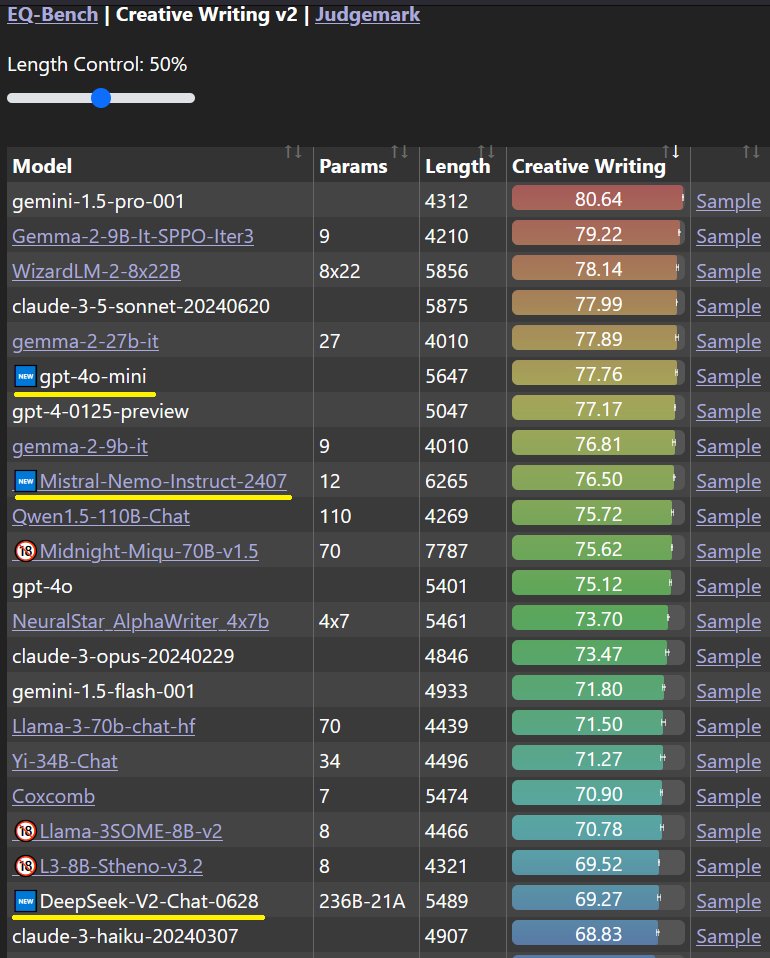
New models benchmarked: - gpt-4o-mini - Mistral-Nemo-12B - DeepSeek-V2-Chat-0628 EQ-Bench Leaderboard (eqbench.com)

(1/8) LLM Model Evals 💪vs LLM Task Evals 🥊 Evals are all the rage 🔥, but they mean different things to different people. The biggest confusion is that there are actually 2 different categories of evals. 1⃣Model evals (ex: HellaSwag, MMLU, TruthfulQA etc) 2⃣Task evals (ex: Q&A from Phoenix Evals: github.com/Arize-ai/phoen…) Model Evals vs Task Evals is the difference between measuring "generalized fitness" 💪 and "specialized fitness" 🥊 Most of us would like to have generalized fitness because it allows us to do a variety of everyday activities well. But if sumo wrestling was your dream, you would obviously prefer to have a much larger body mass. The problem is, most practitioners today are focusing on generalized fitness and getting crushed in the ring ☠️ 🧵 on the differences Tagging folks working on the LLM Model or Task Eval space! @rown @universeinanegg @ybisk @YejinChoinka @allen_ai @haileysch__ @lintangsutawika @hendrycks @markchen90 @MillionInt @HenriquePonde @Shahules786 @karlcobbe @mobav0 @lukaszkaiser

🎓LLM Course This is such a beautiful and comprehensive resource on LLMs. It includes notebooks, key references, and roadmaps. There is something to learn for everyone. For students, researchers, and practitioners. The Prompt Engineering Guide is also referenced, which is cool to see. One observation as I was reviewing the references is how much hard work the ML community dedicates toward open and high-quality education. This resource does a great job of organizing all those incredible LLM educational resources that exist out there. One topic I would add is LLMOps. But to be fair, the majority of the topics are roughly covered in the LLM Engineer Roadmap. Highly recommended! And last but not least, many thanks to @maximelabonne for releasing this excellent resource. 👏


Nancy G @Ayta97188855744
11 Followers 1K Following Flowers grow in my loneliness, dreams in wild silence 🌕
Chen Wang @dr_chenwang
20 Followers 265 Following Principal Researcher @Huawei, previously Research Scientist @BoschGlobal, Ph.D from @INRIA

Andrew Milich @milichab
48K Followers 2K Following @xai @spacex previously @cursor_ai, former CEO @skiffprivacy (acquired by @notionhq)


Ammaar Reshi @ammaar
90K Followers 2K Following Lead Product + Design @GoogleAIStudio // Exploring AI and sharing everything I learn // My views • 🇵🇰 🇺🇸
Logan Kilpatrick @OfficialLoganK
331K Followers 3K Following Member of technical staff, working on Gemini, @GoogleAIStudio, the Gemini API, & Kaggle. My views!

gabriel @gabriel1
101K Followers 582 Following new thing, previously research at @OpenAI & @midjourney

Shunyu Yao @ShunyuYao14
6K Followers 58 Following AI research@DeepMind Prev: @AnthropicAI UG@Tsinghua_Uni, PhD @Stanford and Postdoc @Berkeley
Zara Zhang @zarazhangrui
70K Followers 1K Following Builder. Dangerously skips permissions. Harvard’17. GitHub: https://t.co/KCuEajezlL YouTube: https://t.co/8xzbGWtf6w
Humanlaya @Humanlayadata
31 Followers 22 Following Built by model builders, for model builders. Humanlaya engineers expert-level data and verifiable rewards for frontier AI labs.
Evan Miller @EvMill
5K Followers 215 Following Statistically inclined software developer, occasional blogger about math + stats stuff. Working @AnthropicAI
Jonathan Chang @j_nadan_chang
4K Followers 579 Following Research Scientist @Databricks. Previously @Cornell. Interested in Reinforcement Learning, Imitation Learning, and Generative Models.
Thariq @trq212
282K Followers 2K Following Claude Code @anthropicai. prev YC W20, @southpkcommons, @medialab
Ethan Mollick @emollick
361K Followers 585 Following Professor @Wharton studying AI, innovation & startups. Democratizing education using tech Book: https://t.co/CSmipbJ2jV Substack: https://t.co/UIBhxu4bgq
Riley Goodside @goodside
213K Followers 3K Following Screenshots of chatbots since 2022. Formerly: Google DeepMind, Scale
Evidently AI @EvidentlyAI
3K Followers 211 Following Open source ML and LLM evaluation 📊 , testing 🚦and monitoring 📈 GitHub: https://t.co/37H9bfnYj6 Discord: https://t.co/ElZ9RlroUa
George Hotz 🌑 @realGeorgeHotz
304K Followers 204 Following President @comma_ai. Founder @__tinygrad__
John Carmack @ID_AA_Carmack
2.3M Followers 286 Following AGI at Keen Technologies, former CTO Oculus VR, Founder Id Software and Armadillo Aerospace
snimu @omouamoua
3K Followers 643 Following Leading the RL Residency and training RLMs @PrimeIntellect

stochasm @stochasticchasm
7K Followers 2K Following pretraining lead @arcee_ai • 25 • opinions my own

kalomaze @kalomaze
25K Followers 3K Following ML researcher (@primeintellect), speculator • extremely silly jester


snow @snowclipsed
6K Followers 1K Following cache-miss eliminator @arcee_ai views are my own. https://t.co/h8rzm8QyZc
Meng To @MengTo
171K Followers 425 Following Founder at @designcodeio and https://t.co/Kpiogf2zVu. I teach designers code and developers design.
klöss @kloss_xyz
73K Followers 7K Following AI vibe orchestrator. prompt shaman. systems architect. @psychanon CEO


Gizem Akdag @gizakdag
145K Followers 1K Following Creative Director, AI Explorer || Creative Ambassador @perplexity_ai || For inquiries: [email protected]
Alex Prompter @alex_prompter
278K Followers 1K Following Human + AI = Superpowers 🔑 Sharing AI Prompts, Systems, Tips & Tricks Prev. @godofprompt
Brett @BrettFromDJ
167K Followers 283 Following Running a $1M one-man design studio. 🙂 https://t.co/Bd698tR2Fe: $100K MRR ✍️ https://t.co/qtdiuMA9LP: $12K MRR // Building https://t.co/kbOZ648pJG
Alex Finn @AlexFinn
454K Followers 9K Following Founder/CEO of Henry Intelligent Machines PBC and Creator Buddy. Building a 100 trillion dollar economic engine
@levelsio @levelsio
898K Followers 3K Following 📸https://t.co/lAyoqmSBRX $100K/m 🛰https://t.co/ZHSvI2wjyW $44K/m 🎮https://t.co/jFirUbDgtZ $39K/m 🏡https://t.co/1oqUgfD6CZ $35K/m 👙https://t.co/RyXpqGuFM3 + @X $14K/m 🌍https://t.co/UXK5AFqCaQ $10K/m 💾https://t.co/T74ZwJ1F0C $0/m

jack friks @jackfriks
143K Followers 2K Following curious guy creating things @ https://t.co/HXWladih08 - up and coming wife guy
corbin @corbin_braun
57K Followers 139 Following founder of @thumioapp + @techsnif · yt 174K · music is the answer
Riley Brown @rileybrown
210K Followers 3K Following YouTuber, Educator, Founder Building an agent operating system @chorus_agent Building a marketing agent @text_chorus
GREG ISENBERG @gregisenberg
673K Followers 980 Following I drop startup ideas daily. Host @startupideaspod. CEO: @latecheckoutplz we build companies like @ideabrowser, @meetLCA, @boringmarketer etc
Peter Steinberger �... @steipete
545K Followers 2K Following Polyagentmorous ClawFather. Came back from retirement to mess with AI and help a lobster take over the world. @OpenClaw🦞 + @OpenAI

Sam Paech @sam_paech
4K Followers 226 Following Evals @liquidai Maintainer of EQ-Bench https://t.co/Jy56OlHrP5 https://t.co/oRApPQwvWS
Stephen Roller @stephenroller
6K Followers 1K Following MTS @thinkymachines. previously pre-training @googledeepmind, @character_ai, and @aiatmeta.

Tiezhen WANG @Xianbao_QIAN
11K Followers 3K Following ex-Head of APAC ecosystem @huggingface, interested in future tech. Ex-Googler on TFLite/micro. Ideas are my own. DM me to talk open source and robotics in APAC

Horace He @cHHillee
51K Followers 590 Following @thinkymachines Formerly @PyTorch "My learning style is Horace twitter threads" - @typedfemale
Gary Marcus @GaryMarcus
228K Followers 7K Following OG GenAI Skeptic; spoke at US Senate. Warned about hallucinations in 2001. Advocating world models & neurosymbolic AI ever since. Author, Marcus on AI & 6 booksTrends for United States
You might like



















