

Alexander @pythonicnoise
Joined February 2013-
Tweets523
-
Followers33
-
Following778
-
Likes1K
biggest perk of working at supabase is the balkan slack channel


And another open-weight release. Nemotron 3 Ultra has an ultra impressive capability:efficiency ratio! Design-wise, it carries forward the Mamba-2-attention hybrid stack and LatentMoE introduced in the previous Super variant. But everything is a bit bigger.

It's been a while! 4 nice additions to the open-weight local-LLM-on-consumer-hardware ecosystem:


Highlighting recent advances in multi-GPU and tensor parallel support in llama.cpp Over the last few months llama.cpp maintainers and engineers from NVIDIA collaborated to improve the multi-GPU performance in ggml. This resulted in significant performance gains on RTX systems and laid the groundwork for hardware-agnostic tensor parallelism in ggml. For more information on this and other advancements in the low-level inference engine of llama.cpp, check the technical blog by @NVIDIARTXSpark below

Build on-device personal AI agents on Windows PCs with new tools from NVIDIA and Microsoft, including secure sandboxing, faster local inference, multi-GPU support, and RTX acceleration for Windows AI APIs. Read the technical blog: nvda.ws/4e0rLDN


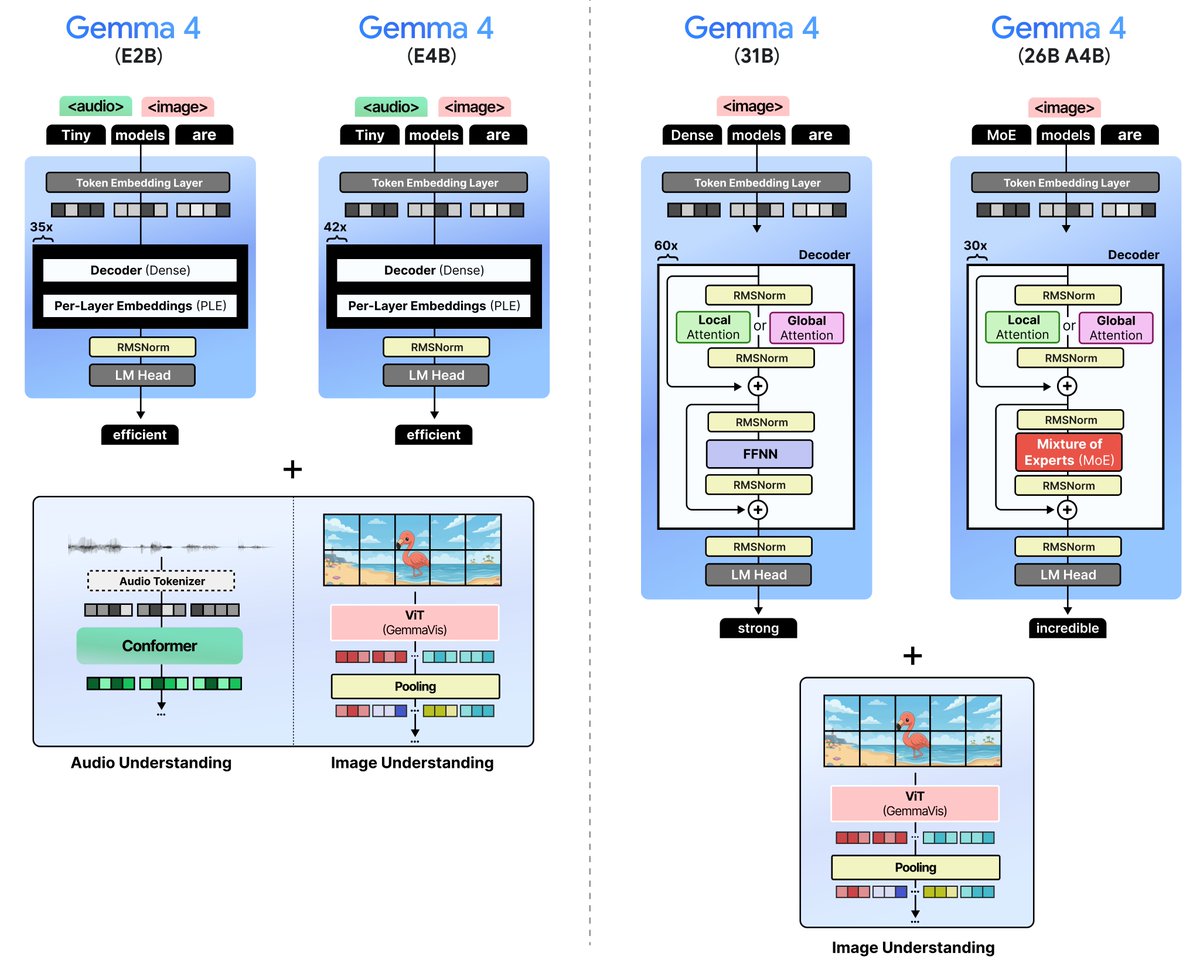
Meet Gemma 4 12B! A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license. Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

llama.cpp now has an official website: llama.app Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications. While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine). We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
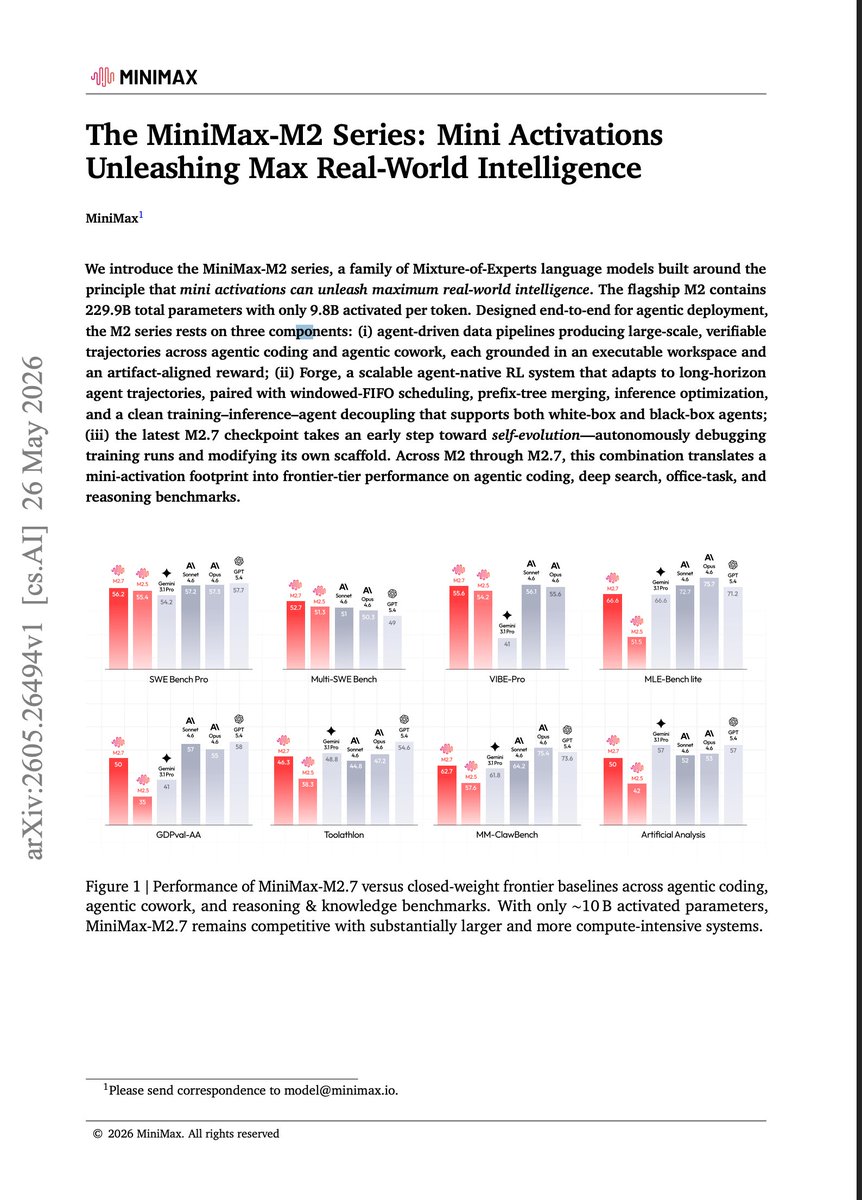
The MiniMax M2 series was one of the most widely used open-weight LLM series earlier this year. Now, we got a technical report with some interesting tidbits. I summarized some of them below: 1. Full attention as an anti-trend?: They tried hybrid sliding-window attention variants (like so many others, like Xiaomi MiMo, Laguna, Gemma 4, Arcee, Olmo 3, etc.). But even though there were efficiency gains, they said that the production-quality tradeoffs were not worth it for M2. 2. Linear and sparse attention deployment issues: They found that linear and sparse attention are attractive on paper because they reduce the cost of long-context attention, but they are harder to make work well in a production agent system. In particular, they found that these efficient attention variants may be more fragile when KV-like state or intermediate memory is stored in lower precision. Also, they have worse prefix caching support, which matters a lot when using coding agents (which reuse a lot of the context). 3. Fine-grained Mixture-of-Experts (MoEs) are useful: Finally a recent MoE ablation study! It's only on the 2B-active parameter scale, but hey, better than nothing. Concretely, they compare a baseline with 32 experts and top-2 routing against a fine-grained setup with 128 experts and top-8 routing. The fine-grained setup improves MATH from 19.6 to 24.1 and HumanEval from 29.7 to 32.5. That's clearly a win for more fine-grained experts (confirming what the DeepSeek MoE paper reported ~2 years ago). 4. Sophisticated agent pipeline It's probably no surprise, but this papers confirms that training for agent-like behavior on software engineering task is now a big component of the training pipeline. They mine GitHub pull requests, builds runnable Docker environments, extracts task-specific test rewards, etc. 5. Interleaved thinking for context management Interestingly, they found that removing reasoning blocks from previous turns results in worse performance, especially in multi-step agent tasks. (Another point why long-context support is so important these days). 6. Speed rewards It's common to have token usage penalties, but what's interesting is that the MiniMax team adds a task-completion-time reward that depends on wall-clock time. This is to minimize unnecessary (slow) tool calls. Also, I'm thinking that this would encourage agent parallelization (if supported by the harness) 7. Self-evolution Looks like self-evolution is also already a big design component of open-weight LLMs. E.g., the paper says that M2.7 already handles 30 to 50 percent of the daily RL iteration workload, modifies its own scaffold, and completed a 100-round autonomous scaffold optimization cycle with a 30 percent gain on internal evaluations.


Recently, we took time to consolidate all of the work behind M2 and published it here: our M2 paper on arXiv It’s been just over six months since we first open-sourced M2 on December 23 last year. During that time, a number of our ideas and systems have been broadly adopted by

Musk hates Altman because Altman deceived him. Altman hates Musk because Musk is an egomaniac. LeCun (who is an equally big egomaniac) hates Musk because Musk is a jerk. Musk hates LeCun because LeCun is a jerk. (He’s not wrong.) None of these people are heroes. All routinely take credit for other people’s work; none are honest. And not one of them lives up to their own standards. There a few decent people in AI left – like Hassabis – but not as many as we need.
Added a DeepSeek Sparse Attention (DSA) from-scratch implementation to my LLMs-from-scratch repo thanks to an awesome new reader contrib. With motivation, overview, and GPT-style model reference implementation as standalone example code: github.com/rasbt/LLMs-fro…


Two Bulgarian friends killed the entire streaming industry. It's called Stremio + Torrentio. You get 4K content from Netflix, Disney+, Hulu, and HBO Max combined for free. Here's how it works. Stremio is the player. Clean interface. Works on Windows, macOS, Linux, Android, iOS, and TV. You install it once and it looks like any other streaming app. Torrentio is the addon. You add it to Stremio in one click. It scrapes content from every major torrent provider on the internet simultaneously and delivers the best available stream directly to your player. 720p, 1080p, 4K. You pick the quality. It finds the link. → No account required → No subscription → Works on every device → 4K and HDR supported → Subtitles built in Netflix cannot shut this down. There is no central server to seize. No company to pressure. No domain to kill. It runs on your device and pulls from the open internet. The entire streaming industry is built on one assumption. That you will keep paying $70/month rather than spend 5 minutes on GitHub. That assumption just died in Sofia, Bulgaria. MIT License. 100% Opensource. github.com/Stremio/stremi… Get the addon here: stremio-addons.com/torrentio.html

@karpathy Congrats on the next thing! Most importantly: have fun with Research & Development. (I will try to keep up with the Reproduce & Debug part :D) Looking forward to learn from your learnings at the frontier.

If only every foundational LLM lab would publish such a guide with their model releases.
A Visual Guide to Gemma 4 With almost 40 (!) custom visuals, explore the new models from Google DeepMind. We explore various techniques, ranging from Mixture of Experts and the Vision Encoder all the way up to Per-Layer Embeddings and the Audio Encoder. Link below 👇

"Using coding agents well is taking every inch of my 25 years of experience as a software engineer, and it is mentally exhausting. I can fire up four agents in parallel and have them work on four different problems, and by 11am I am wiped out for the day. There is a limit on human cognition. Even if you're not reviewing everything they're doing, how much you can hold in your head at one time. There's a sort of personal skill that we have to learn, which is finding our new limits. What is a responsible way for us to not burn out, and for us to use the time that we have?" @simonw
"Using coding agents well is taking every inch of my 25 years of experience as a software engineer." Simon Willison (@simonw) is one of the most prolific independent software engineers and most trusted voices on how AI is changing the craft of building software. He co-created

BREAKING Elon Musk endorsed my Top 26 Essential Papers for Mastering LLMs and Transformers Implement those and you’ve captured ~90% of the alpha behind modern LLMs. Everything else is garnish. This list bridges the Transformer foundations with the reasoning, MoE, and agentic shift Recommended Reading Order 1. Attention Is All You Need (Vaswani et al., 2017) > The original Transformer paper. Covers self-attention, > multi-head attention, and the encoder-decoder structure > (even though most modern LLMs are decoder-only.) 2. The Illustrated Transformer (Jay Alammar, 2018) > Great intuition builder for understanding > attention and tensor flow before diving into implementations 3. BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018) > Encoder-side fundamentals, masked language modeling, > and representation learning that still shape modern architectures 4. Language Models are Few-Shot Learners (GPT-3) (Brown et al., 2020) > Established in-context learning as a real > capability and shifted how prompting is understood 5. Scaling Laws for Neural Language Models (Kaplan et al., 2020) > First clean empirical scaling framework for parameters, data, and compute > Read alongside Chinchilla to understand why most models were undertrained 6. Training Compute-Optimal Large Language Models (Chinchilla) (Hoffmann et al., 2022) > Demonstrated that token count matters more than > parameter count for a fixed compute budget 7. LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023) > The paper that triggered the open-weight era > Introduced architectural defaults like RMSNorm, SwiGLU > and RoPE as standard practice 8. RoFormer: Rotary Position Embedding (Su et al., 2021) > Positional encoding that became the modern default for long-context LLMs 9. FlashAttention (Dao et al., 2022) > Memory-efficient attention that enabled long context windows > and high-throughput inference by optimizing GPU memory access. 10. Retrieval-Augmented Generation (RAG) (Lewis et al., 2020) > Combines parametric models with external knowledge sources > Foundational for grounded and enterprise systems 11. Training Language Models to Follow Instructions with Human Feedback (InstructGPT) (Ouyang et al., 2022) > The modern post-training and alignment blueprint > that instruction-tuned models follow 12. Direct Preference Optimization (DPO) (Rafailov et al., 2023) > A simpler and more stable alternative to PPO-based RLHF > Preference alignment via the loss function 13. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022) > Demonstrated that reasoning can be elicited through prompting > alone and laid the groundwork for later reasoning-focused training 14. ReAct: Reasoning and Acting (Yao et al., 2022 / ICLR 2023) > The foundation of agentic systems > Combines reasoning traces with tool use and environment interaction 15. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (Guo et al., 2025) > The R1 paper. Proved that large-scale reinforcement learning without > supervised data can induce self-verification and structured reasoning behavior 16. Qwen3 Technical Report (Yang et al., 2025) > A modern architecture lightweight overview > Introduced unified MoE with Thinking Mode and Non-Thinking > Mode to dynamically trade off cost and reasoning depth 17. Outrageously Large Neural Networks: Sparsely-Gated Mixture of Experts (Shazeer et al., 2017) > The modern MoE ignition point > Conditional computation at scale 18. Switch Transformers (Fedus et al., 2021) > Simplified MoE routing using single-expert activation > Key to stabilizing trillion-parameter training 19. Mixtral of Experts (Mistral AI, 2024) > Open-weight MoE that proved sparse models can match dense quality > while running at small-model inference cost 20. Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints (Komatsuzaki et al., 2022 / ICLR 2023) > Practical technique for converting dense checkpoints into MoE models > Critical for compute reuse and iterative scaling 21. The Platonic Representation Hypothesis (Huh et al., 2024) > Evidence that scaled models converge toward shared > internal representations across modalities 22. Textbooks Are All You Need (Gunasekar et al., 2023) > Demonstrated that high-quality synthetic data allows > small models to outperform much larger ones 23. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Templeton et al., 2024) > The biggest leap in mechanistic interpretability > Decomposes neural networks into millions of interpretable features 24. PaLM: Scaling Language Modeling with Pathways (Chowdhery et al., 2022) > A masterclass in large-scale training > orchestration across thousands of accelerators 25. GLaM: Generalist Language Model (Du et al., 2022) > Validated MoE scaling economics with massive > total parameters but small active parameter counts 26. The Smol Training Playbook (Hugging Face, 2025) > Practical end-to-end handbook for efficiently training language models Bonus Material > T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019) > Toolformer (Schick et al., 2023) > GShard (Lepikhin et al., 2020) > Adaptive Mixtures of Local Experts (Jacobs et al., 1991) > Hierarchical Mixtures of Experts (Jordan and Jacobs, 1994) If you deeply understand these fundamentals; Transformer core, scaling laws, FlashAttention, instruction tuning, R1-style reasoning, and MoE upcycling, you already understand LLMs better than most Time to lock-in, good luck!

@Could_Flyyy Ползвайте openevidence.com

I just implemented Google’s TurboQuant for vLLM. My USB-charger-sized HP ZGX now fits 4,083,072 KV-cache tokens on GB10. This may be the biggest open inference breakthrough of 2026 so far. Training is the flex. Inference is the forever bill.


When I was consulting for @HBO Silicon Valley, zero-loss compression was the holy grail Richard Hendricks chases that perfect middle-out algo could shrink everything w/out breaking a single bit. Google just did something even more practical for the AI era: TurboQuant compresses LLM key-value caches down to 3 bits per value using random orthogonal rotation + PolarQuant scalar quantization & optional 1-bit QJL residual correction. =>> 6× memory reduction, up to 8× faster attention (on H100), & 0 degradation on LongBench, Needle-in-a-Haystack, and RULER for models like Gemma. No retraining, no calibration needed. Fiction just got out-engineered by reality. 😅💚💚


Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
In the next version of Claude Code.. We're introducing two new Skills: /simplify and /batch. I have been using both daily, and am excited to share them with everyone. Combined, these kills automate much of the work it used to take to (1) shepherd a pull request to production and (2) perform straightforward, parallelizable code migrations.


Next Thursday, I have my first customer demo. Now I packed my algorithms into a product - see the full scan at the end 👀. Runs real time (+200Hz) on device, no-GPS. The first step towards fully auto. robots that understand. Building the API for the physical world!

1983 Steve Jobs understood stock options on a level most CEO still don't

tang | AI Product Mak... @justic_hot
235 Followers 522 Following Solo dev shipping with AI. Built https://t.co/LdYnvQhuaN (AI video) + ShrimpFarm (open forum). What works, what breaks, what I'd skip next time.
Clemence @J2FMWiyJy884n
159 Followers 6K Following
Lia @Lia_thetrrader
211 Followers 4K Following Founder & CEO @TMADFinance - Private Trading Community. Author ✍️ MSc. @Columbia University 🎓 featured: @wsj @nbc @forbes @esquire @usatoday JOIN US:
Ian Hill @IanHill
238 Followers 590 Following Founder and CEO of Palpable AI - the first Voice-Only AI assistant that Gets. Stuff. Done... better than humans: https://t.co/2KSzZEbOUH

Awvexalp @Awvexalp225522
46 Followers 1K Following
b @bolgradov_b
1 Followers 7 Following
Kristy Mertz @MertzKrist58486
77 Followers 3K Following
LisaSavigano @LisaSavigano
437 Followers 896 Following Yellow brick blabbermouth. Жълтопаветнa алабалистка.
Ivan Raikov @iraikov@... @IvanRaikov7
209 Followers 2K Following
Valentinoriant | ETHG... @iandrianthira
2 Followers 390 Following You are now invited to join a (cryptocurrency) discussion group created by an international team of financial analysts. ws link:https://t.co/zhSTZFH0vR

Mike Dougherty @doughertym
5K Followers 4K Following ‘The world is full of magic things, patiently waiting for our senses to grow sharper.'― W.B. Yeats https://t.co/4FQ0muBjHV
kineticum @kineticum_WEC
4 Followers 43 Following Offical X account of https://t.co/oSVGON0yxY. Providing data-driven understanding of the World Endurance Championship

Mary Cher: immortalis... @ActivistCher
590 Followers 4K Following Product & marketing manager in medicine. Longevity volunteer. I'd like to clone myself. #SayForever! #MarsNeedsLongevity #TGdiaryMC - my transhumanistic diary)
Uncle B 😎 @brygsi
3K Followers 2K Following Motorcycles, Philosophy, Adventures. opinionated sometimes. Awake not woke. All tweets are not my own.Ok some are. Be real,best you can,anyway. No DM’s 🙏🏻

Dylan Frank @DylanFrank21
893 Followers 713 Following 15yr athlete and news reporter. Follow for news 📰 on Global conflicts. Unbiased news coverage. All sources are verified no BS. Follow my TikTok ↘️
lovelovebulgaria @lovelovebulgar1
2K Followers 2K Following Обичам България😍Искам да знам много за България😍 Аз съм изследовател на аутизма в Япония. Синът ми също обича България @takenokokun3 😁
Mladen Marev 𝕏 @mladenmarev
366 Followers 505 Following In the middle of nowhere in England North West. VP, Head of Cyber & Security in Digital @Barclays
vasbel @vasbelyak
687 Followers 766 Following “No pleasure has any savor for me without communication.” MdM
Sheikh Muhammad Sarwa... @zzz2aaa
234 Followers 448 Following Applied Scientist @ Amazon Alexa Shopping Research. PhD from CIIR, UMass Amherst.

veeeebzn @veeeebzn
16 Followers 85 Following
vaex @vaex_io
2K Followers 174 Following Out of core dataframes for Python, visualize and explore big tabular data at a billion rows per second. ML ready. https://t.co/GmNIpbuNlY @maartenbreddels @JovanVaex
LoveHate @lovehatemfg
1K Followers 811 Following Not hungry, not homeless... just need booze, gas and Harley parts! OWOF

Silvia Bakalova @SilviaBakalova
3 Followers 21 Following

Harrison Kinsley @Sentdex
105K Followers 420 Following gpus and tractors. Director of AI and Engineering @ https://t.co/H4St8dd1ip Neural networks from Scratch book: https://t.co/hyMkWyUP7R https://t.co/8WGZRkUGsn
Peter Wang @BrainsAndTennis
10K Followers 42 Following Founding scientist @fundamental co-founder and chief science officer @tryshortcutai
Henrick Johansson @compliantvc
552K Followers 255 Following European VC in USA | Author of 'European Dynamism' | Investing in compliant startups | Advisor @compai | Managing Partner @ Compliant Capital
Jane Manchun Wong @wongmjane
180K Followers 3K Following “The woman scooping Silicon Valley” — BBC・hacker turned builder, writer & consultant・prev: Threads, Instagram, startups
Lilian Rincon @lilianr
9K Followers 805 Following VP of product for Apple AI WW @Apple, Past: Google, Microsoft, Skype 🇻🇪🇨🇦🇮🇩🇺🇸, 🏐, ⚽️, 🎼
Kimi Developers @KimiDevs
57K Followers 1 Following The official Kimi account for developers building with Kimi Code and the Kimi API.
Javi Lopez ⛩️ @javilopen
128K Followers 2K Following Founder at @Magnific_AI (acq. by @Magnific formerly @freepik)
Doug Finke @dfinke
12K Followers 2K Following Systems Architect | 16-time Microsoft MVP | Author: PowerShell for Developers | Building Agentic AI & MCP Workflows
Maarten Grootendorst @MaartenGr
9K Followers 38 Following 🧑💻 AI @GoogleDeepMind 📖 Author of "Hands-On LLMs" (https://t.co/BcSDNMOnWq) 🧙♂️ Open Sourcerer (BERTopic, PolyFuzz, KeyBERT) 💡 Demystifying AI
Alok @analogalok
827 Followers 185 Following Mechatronics Engineer AI belongs on your device. • Offline inference • No subscriptions. Teaching you to own your AI Intelligence Stack
jordi @jordienr
7K Followers 813 Following swe o11y @supabase // @zenblogHQ // https://t.co/WTF6Vh1Ic6 // https://t.co/itEHw8Y9jV // https://t.co/vw8HfkxktK // https://t.co/THHfnv0PTE
Nous Research @NousResearch
208K Followers 26 Following A bunch of nerds making progress toward open source AI https://t.co/vrD0aDJeto
Alex Lieberman @businessbarista
306K Followers 4K Following Family first (husband & girl dad) Founder second (@tenex_labs, @morningbrew, @storyarb, @youdistro) AI engineering & transformation 👇
constantin @luckenco
598 Followers 177 Following Head of Prosperity ⌯ I babysit LLMs for a living ⌯ Live on Thursdays 5pm UTC with https://t.co/Pc0oWkKWwk
Drew Miko @xdrewmiko
920 Followers 244 Following Currently building https://t.co/1ldtI8VTQM Path to $20K MRR | Sharing what actually works https://t.co/WdINReySy2 https://t.co/NcPHYFx7eO https://t.co/NupovzrNne https://t.co/C48GAnZX3U https://t.co/kpUK4FVRxQ
Evan @evan_thayer
2K Followers 184 Following I make parts & assemblies for mechanisms, machines, and artwork. Ex-Apple where I made retail stores around the world. Licensed architect, amateur poster.



Dr. Julie Gurner @drgurner
186K Followers 9K Following Executive Performance Coach. Doc of Psych. Compared to Wendy Rhoades of Billions via WSJ. Newsletter: https://t.co/EH1oxypq9r Inquiries: ⬇

Daniel Lockyer @DanielLockyer
60K Followers 143 Following • I make sites faster and cloud/LLM bills lower 🚀 • 2:43 marathoner (🔜 2:39 in Berlin)

Antoine Rousseaux @AntoineRSX
47K Followers 2K Following Market observer. Building SaaS and Ai Agents.

Giorgia Meloni @GiorgiaMeloni
3.5M Followers 250 Following Presidente del Consiglio dei Ministri della Repubblica Italiana
Nick Khami @skeptrune
16K Followers 5K Following currently doing things at Mintlify, prev. trieve acq. YCW24, you should try to fail faster
Morgan @morganlinton
38K Followers 780 Following cto @boldmetrics / prev: @sonos, @carnegiemellon / sf digital real estate investor: https://t.co/39bVURL7oJ, https://t.co/zPTfgfHXDO, https://t.co/jQpZftFl6B ++
Mike Bradley @The_Only_Signal
10K Followers 291 Following Free and open source local AI research and tools.
Julian Harris @julianharris
6K Followers 4K Following https://t.co/Q3TocdANjY: agent harness with rules engine. Ex-Google, 2 boys, muso.
Aaron Francis @aarondfrancis
61K Followers 2K Following Sincere poster. No cynicism. Dad to two sets of twins! - https://t.co/WfYvVaHpTW - https://t.co/QG0tWQcm92 - https://t.co/RuC1MT0UuJ - @MostlyTechPod
Emil A. Georgiev @emilageorgiev
6K Followers 346 Following Attorney. Judicial reform in Bulgaria. Pro-EU, Transatlanticist, #Nafo. My #BlueSky profile - https://t.co/bgcTJ6uULG

Rohit @rohit4verse
23K Followers 497 Following Engineer who builds, solves, and ships | FullStack + Applied AI | Agentic AI |
am.will @LLMJunky
26K Followers 2K Following StarSwap // Life in Color Director of n number of agents. Thoughts are my own. Also not a car.


ClaudeDevs @ClaudeDevs
480K Followers 3 Following Official updates for developers building with @ClaudeAI

Claude Code Changelog @ClaudeCodeLog
69K Followers 20 Following UNOFFICIAL – but tolerated – bot posting Claude Code CLI, feature flag & prompt changes. Full CC history in github repo.
Demis Hassabis @demishassabis
1.1M Followers 172 Following Nobel Laureate. Co-Founder & CEO @GoogleDeepMind - working on AGI. Solving disease @IsomorphicLabs. Trying to understand the fundamental nature of reality.
Riley Goodside @goodside
211K Followers 3K Following Screenshots of chatbots since 2022. Formerly: Google DeepMind, Scale.
DAIR.AI @dair_ai
126K Followers 1 Following Democratizing AI research, education, and technologies. Learn about AI Agents for FREE at https://t.co/HHXg8rryu4
tang | AI Product Mak... @justic_hot
235 Followers 522 Following Solo dev shipping with AI. Built https://t.co/LdYnvQhuaN (AI video) + ShrimpFarm (open forum). What works, what breaks, what I'd skip next time.
Mind Enterprises @MindEnterprises
35K Followers 64 Following Best summer ever? Italia ‘90! ✊ IDOL T-SHIRT👇https://t.co/tvdyTe4Be8

ani @anirudhbv_ce
7K Followers 258 Following 19, incoming @nvidia / ml @sentra_app (a16z) | prev. ml @shopify @voiceflow | mlh top 50 | uwaterloo ce '30
Ventusky @Ventuskycom
25K Followers 2K Following We focus on weather prediction and meteorological data visualisation. Our goal is to improve awareness about meteorological events in our atmosphere.
euan ashley @euanashley
8K Followers 771 Following Stanford Chair of Medicine | Author of The Genome Odyssey | Founder of biotechnology companies | Board member AstraZeneca, Dexcom
Clelia Bertelli (🦙... @itsclelia
913 Followers 412 Following she/her | Member of Technical Staff at @llama_index 🦙 | Girly dev building AI things in python💅 | Cheating on python with Go and Rust🦫🦀You might like







