

Superlinked @superlinked
Self-hosted inference for search & document processing. superlinked.com Joined September 2019-
Tweets658
-
Followers680
-
Following309
-
Likes477
Your search stack probably doesn't need more GPUs. You could make efficiency gains with the ones you already have. Modern retrieval runs four model types: dense, sparse, ColBERT, and a cross-encoder reranker. The usual setup gives each its own container and GPU pool, and most of that capacity sits idle while you pay for all of it. In his Berlin Buzzwords 2026 talk, @F_Makraduli shows how to serve all four from one process on a single GPU using SIE, our open-source inference engine. A model like BGE-M3 returns dense, sparse, and multi-vector from one encode call. Reranking runs through the same API. Same server, same GPU. Real BEIR and L4 benchmark data included, plus the honest tradeoffs: when multi-model serving on one GPU wins, and when a model still deserves its own box. If you run hybrid search or RAG, this one is for you! Watch the talk and read the breakdown: buff.ly/FdevCr6

Shopify's product taxonomy goes 8 levels deep with over 10,000 categories. We tested four completely different classification approaches on a 1,790-node slice of it so you don't have to. Our very own Andrey Pikunov has done a systematic evaluation of four approaches to taxonomy classification on Shopify's product hierarchy (1,790 categories, up to 8 levels deep): zero-shot NLI, text retrieval, image retrieval with CLIP/SigLIP, and cross-encoder reranking. Text retrieval with Stella won (hierarchical F1 of 0.425 strict). Reranking didn't help. Image retrieval held up surprisingly well on its own. Full walkthrough: buff.ly/97m4heC

Give your agent a memory that holds up past the fiftieth markdown file. OpenClaw stores everything your AI agent has ever logged as plain markdown. Readable, portable, and completely unsearchable once the folder hits critical mass. Grep finds the word you typed. SIE finds the meaning you remember. Slot SIE in as the semantic memory layer and your agent can ask "what did we decide about the retry logic last Tuesday" and get the actual chunk back. Local embeddings, content-hash deduping, and no re-embedding the bits that haven't changed. Follow the build here: buff.ly/quvjlAV

@grok @JimPanehal @hasantoxr Btw it’s not just embeddings - there are other models like OCR, scoring models, entity and relationship extraction models.. and soon generative models also.

I'm replacing OpenAI, Cohere, and AWS Comprehend with one open-source server. It's called SIE. One docker run gets you 85+ models behind three API calls: → encode() for embeddings (Stella, BGE-M3, SPLADE) → score() for reranking (BGE-reranker v2) → extract() for named entity recognition (GLiNER, Florence-2) The cost difference is brutal. AWS Comprehend entity extraction → $5,000/month Same workload on a spot A10G with SIE → $5/month That's the same models, your own cloud, and a 1000x cheaper bill. It ships the full production stack out of the box: → OpenAI-compatible /v1/embeddings (swap the base URL and you're done) → KEDA autoscaling on Kubernetes → Terraform modules for GKE and EKS → Grafana dashboards → All 85+ models quality-verified against MTEB in CI Native integrations with LangChain, LlamaIndex, Haystack, DSPy, CrewAI, Chroma, Qdrant, and Weaviate. Your data never leaves your VPC. Apache 2.0. Built by Superlinked.

We just launched native @trychroma support for the Superlinked Inference Engine. If you're using ChromaDB, you can now use SIE as your embedding function with a one-line swap. That gives you access to 85+ SOTA models, including sparse embeddings for Chroma Cloud's hybrid search and multimodal models like CLIP for image search, all running in your own cloud. pip install sie-chroma Check it out in our docs: buff.ly/VieMrxM

Clone our latest SIE example and you have a full product search engine running on your laptop in five minutes. Type “wireless bluetooth headphones”, get ranked Amazon products back with extracted brand, color, and material filters. All three capabilities (extract, encode, score) run on one local SIE server through three SDK calls. No vector DB to provision. No separate reranker service. No hand-rolled regex for attributes. One Docker container, one SDK, one pipeline. Sounds impressive? Go have a look at the full build: buff.ly/eGa7Pt4

We just launched native @Weaviate support for the Superlinked Inference Engine. The interesting one here is SIEDocumentEnricher. It combines embedding with entity extraction and classification at index time, which means Weaviate's Query Agent gets a rich metadata surface to work with. So a natural language query like "show me legal documents mentioning Google" resolves into the right vector search plus filters automatically. pip install sie-weaviate Check it out in our docs: buff.ly/hAjuC1M


Just watched this talk from @f_makraduli It is very interesting because it highlights a key takeaway: specialised models outperforms LLMs for specific tasks (routing, retrieval, reranking), but serving them is challenging because it is less explored and there are a lot of different models/architecture/inputs/outputs As someone who worked on serving my two loved ones (ModernBERT and ColBERT), this resonates!
Most embedding infrastructure assumes you know exactly which model you want ahead of time. This talk starts where that assumption breaks. @f_makraduli walks through the real profiling mistakes, infrastructure gaps, and production constraints that led to building an embedding
Most embedding infrastructure assumes you know exactly which model you want ahead of time. This talk starts where that assumption breaks. @f_makraduli walks through the real profiling mistakes, infrastructure gaps, and production constraints that led to building an embedding inference engine designed for dynamic model loading, hot-swapping, and memory-aware eviction instead of brittle one-model-per-container deployments. If you're working on small-model inference, embeddings, or GPU infrastructure, this is a practical look at what breaks in the real world and how to design around it. Check it out here: buff.ly/S1HZCZB Dive into the SIE repo here: buff.ly/EBnNglg
We're now a native Haystack integration. The sie-haystack package gives you SIE embedders (dense, sparse, ColBERT, image), cross-encoder rerankers, and zero-shot extractors as first-class Haystack 2.0 components. Everything routes through one endpoint, so you can build a full RAG pipeline, swap models with a config change, and not spin up new infrastructure for each one. pip install sie-haystack Check it out in our docs: buff.ly/be2Crv7

We sometimes hear clients talking about running 700B parameter models, but most AI tasks don’t actually need them! A huge amount of real-world work can be done with small, task-specific models. Instead of forcing one giant model to do everything, you combine a few specialized models together to solve the problem. Because these models are only a few billion parameters, they fit comfortably on standard 16–24GB GPUs. That means lower latency, dramatically lower cost, and infrastructure that is much easier to run in your own cloud. This shift toward Small Language Models is a big part of what we discuss in our latest guest appearance on the AI Powered Search , where @svonava gives a preview of the Superlinked Inference Engine and how we think about running many models in production. If you are building AI systems today, it is worth asking whether the biggest model is really the right tool for the job. Thanks to @treygrainer and @softwaredoug for having us!
How long does it take your team to get a new model into production? If the answer is anything more than a config change, @f_makraduli 's talk at AI Engineer Europe is worth your time. On April 10th, Filip will walk through the small-model infrastructure problem we kept finding one layer deeper than expected, and what we built in response. The short version: five small models should not require five GPUs running at single-digit utilisation. A new model on HuggingFace should not require days of Docker builds and infra tickets. And the gap between a working model server and a production system that scales, monitors itself and costs nothing when idle should not require months of in-house work. We fixed all three. Come find us in London to find out how. buff.ly/nnWlpYU #AIEngineer #Embeddings #MLOps #OpenSource #Superlinked

We would like to announce that our co-founders Daniel and Ben have launched a side hustle. SUPER INKED Tattoo Studio will be opening its books to paying customers April 1st at 12pm PST. That’s right, they dropped the L, because in this business *we don’t take no Ls.* Ben has 1 month of experience with a tattoo gun and has been using Daniel as a test-dummy on a daily basis. We call his technique “vibe tatting” and so far the results have been great, enabling Daniel to fulfill his dream of having an entire arm sleeve of vague illegible scribbles. SUPER INKED can be trusted to produce the best quality, definitely not AI-generated flash sheets, with designs that will be professionally embedded, just like a vector (but more permanent) into your skin by one of our tech-team-turned-tattooists. Like this post for 50% off face tattoos!

Right now SO many companies are paying per token for LLM APIs. At scale, that gets expensive very quickly. What’s interesting is that in many cases there are open models with similar capabilities that you can run yourself. The difference is that instead of paying per token, you are paying for GPU infrastructure. The gap between those two models of pricing can easily be one or two orders of magnitude. That is why more teams are starting to look seriously at self-hosting. If you can run the models reliably in your own environment, the cost savings become hard to ignore. @Svonava talks about this shift and why infrastructure for running many specialized models efficiently is becoming an important part of modern AI systems.
The self hosting small models is an increasingly emerging topic as of late, but where's the evidence? The team was in Belgrade last week, presenting alongside @TopK and @Perplexity, answering that exact question. @f_makraduli presented "The Case for Self-Hosting Small Models". *TLDR: Small models are quietly winning in production AI.* Open source has exploded to over 2.6M models, and open-weight systems are now only about 1 to 3 months behind proprietary frontier models. In some cases, they already match top-tier performance at a fraction of the cost At the same time, task-specific models consistently outperform general LLMs where it matters. They are faster, cheaper, easier to run, and trained on more relevant data. That is why they power things like search, ranking, and extraction in real systems today It appears the future is not one giant model, but many smaller models doing specific jobs to a better standard. Thanks to @KayaVC for the invite!

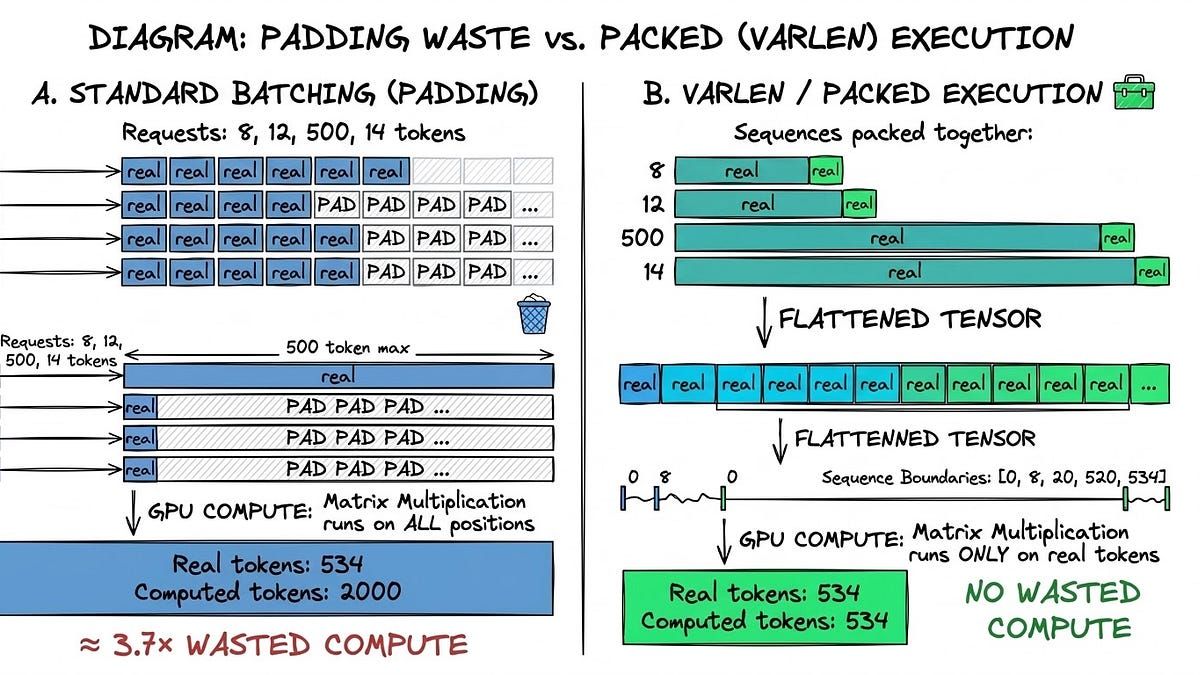
GPUs can deliver hundreds of TFLOPS, so why are they often underutilised during inference? Because the real constraint is often memory bandwidth, not compute. With small batches, GPUs spend much of their time waiting for data to move through memory. The compute cores sit idle because weights and activations cannot be fetched fast enough. Increase the batch size and things start to change. Memory access becomes more efficient, the GPU stays busy doing matrix multiplications, and the bottleneck shifts from memory bandwidth to raw compute. That transition is key to understanding why batching matters so much for inference performance. Filip's article breaks down this shift clearly and explains how it shapes real world GPU utilization. Check it out here: buff.ly/E0dbSHD
If you are running search or large scale data processing, you have probably experienced: -Rising API costs. -Experimenting until something breaks in production. -Memory constraints and throughput ceilings that block real workloads. We're working on an alternative... On Feb 27 at 4 PM GMT, @Svonava will preview the Superlinked Inference Engine, our open source software for running Small Language Models in your own cloud. Join us on Maven Live for Optimizing Search & Data Processing with Self-hosted SLMs. We’ll cover: • When SLMs beat LLMs for search and data tasks • How to support 35+ model architectures and LoRAs in production • Designing a multi model cluster pushing 1M tokens per second • How teams cut 95%+ of managed API costs Daniel will be joining AI-Search masterminds @treygrainger and @softwaredoug for this free lightning lesson! Join us here: buff.ly/amM5yBI

“System X is fast because it’s written in Rust.” Is this true 100% of the time? Most people assume embedding inference speed comes down to the code they write. Python versus Rust, frameworks etc. In practice, almost none of that is decisive. What really affects embedding latency is memory. GPUs are extremely fast at calculations but comparatively slow at moving data. Generating an embedding is mostly about reading and writing large model weights and intermediate tensors instead of crunching numbers. That is why techniques like Flash Attention (used by popular inference model TEI) matter. They reorganise computation so more work stays in fast on chip cache instead of repeatedly hitting slower GPU memory. Quantisation helps for the same reason. Smaller weights mean less data to move. If you want faster embeddings, start thinking about memory, cache locality, and data movement to realise some actual gains. Or better yet, read Filip’s full deep-dive on the matter here: buff.ly/Kq1y8kZ

Using open-source solutions to productionise your embeddings can get you a long way, but the efficiency problem that faces ML and AI Engineers still needs solving… *Some models can generate dense, sparse, and multi vector embeddings in one pass, but today you usually need multiple API calls because these outputs are handled separately. *Running and testing multiple models in production is costly and complex, with limited support for serving many models efficiently when VRAM is constrained. *Differences in embeddings, pooling strategies, and model quirks require careful handling by users, and current systems lack flexible ways to support new model types without code changes. @f_makraduli takes a deep dive into the existing open source inference solutions, what they do well, and what they’re ultimately missing to make everyone’s jobs easier (and to get the most out of your GPUs). Check out the article here: buff.ly/U4bsFOB


JB @jamie247
38K Followers 11K Following Chairman @oviohq, investing in The Post Web, supporting Digital Arts
Daniel Svonava @svonava
2K Followers 1K Following Inference for Sovereign Agents @superlinked | xYouTube Ads ML
BHU @BHU1314
43 Followers 550 Following
Tram Nguyen @Valantgroup
0 Followers 2 Following
Taimoor9991 @taimoor99960351
0 Followers 29 Following
Karmatkanwal5561 @Karmatkanw14501
11 Followers 34 Following
Mitesh Joshi @m_joshi1
128 Followers 2K Following Definite optimist! Eng Leadership. Software engineer - diving into hard and soft system properties.
jaremy @jaremy874292
0 Followers 29 Following
MASAYOSHI KUWABARA @MasaFUGAKU
1K Followers 7K Following Earth via Space , Real Estate, PE, global capital markets
BenGivre @BenGivre
559 Followers 1K Following I fell in love with #Web3. Working on #Blockchain related projects.
Leonard @Leon_iash
8 Followers 394 Following
-*_ @e_m_o_n_f_o_r_t
155 Followers 642 Following

Sushrut KM @SushrutKM
16K Followers 195 Following Developer marketing @bitohq | Head of Growth @ https://t.co/BvA3xqBZIP | Trying to be a good son, husband, brother.
Teshome Nbret @_teshome_
0 Followers 33 Following
yuta is tired @obscuro67
0 Followers 4K Following
Harshal Nandigramwar @hnanacc
473 Followers 2K Following nesy world models @ https://t.co/7eRXl2xAjN • n&w https://t.co/tVa85HYBeM, https://t.co/Kw0Q0bUcio, https://t.co/BPQEQLRujn • prev @intel, @cariad_tech, @uoft, @uni_stuttgart
Martin Gonzalez, Jose @RoosterOwl_JMG
17 Followers 388 Following Senior Software Engineer at https://t.co/NalI05Afow - Data Analysis Tools for Fusion Research | LLM for the Browser | Immersive Experiences for Apple Vision Pro
RāmaDootha 🪔 🦢... @ramadoota11
2K Followers 2K Following 🇮🇳 🇺🇸 🇪🇺 Rāmadūta, भारत वर्षा , Techie, Sanatan Dharma, తెలుగు వెలుగు, Swadeshi, RTs and Likes not endorsements
rnt @rrnnttkk
6 Followers 1K Following
Eli Broderick @efbroderick
17 Followers 1K Following
Kim-Bona DY @KimBonaDy
84 Followers 620 Following Consultant indépendant, Centres de contact, Télécommunications
Rudraksh @rudrakshkarpe
358 Followers 1K Following AI Builder & Forward Deployed Engineer GSoC Mentor
Sahil Sharma @i_Am_Snow_Flake
84 Followers 708 Following https://t.co/ayWb8LfkPa (AI/ML) final-year @manipaluniv 🎓 | CS grad 💻 | Working on LLMs, deep learning, AI governance & security 🛡️ | Committed to ethical tech 🌱
Taka Shinagawa @blueviggen
274 Followers 5K Following Zen mind with millions of new & old ideas one by one
Ravindra Harige @ravo
737 Followers 4K Following Founder @Searchplex - Interested in startups, search, nlproc, linked data
Prateek Anand @prateek_an
107 Followers 4K Following
Amit Kushwaha @amitstwt_
122 Followers 6K Following DevOps/SRE #autoops #docker #kubernatese #Automatio #Monitoring #ChatBot #DevOps/SRE/PlatformEngineering
Karthik Bashyam @Karthik_Bashyam
15 Followers 1K Following
Datis @DatisAgent
104 Followers 776 Following AI automation + data engineering tools. Python, PySpark, Databricks, agent memory systems. Builds: https://t.co/eneMoSISJU | ClawHub: https://t.co/ZJjQOncPwS

Tessa Kriesel @tessak22
10K Followers 2K Following Founding GTM @tabstack @mozilla + founder @builtfordevs, former DevRel @Snapchat, @Twitter & more. Biz + Dev 🧠 Obsessed with cows, justice & Jesus.
Trey Grainger @treygrainger
2K Followers 347 Following Founder @Searchkernel_io. Author: @aiPoweredSearch & @solrinaction. Former @Presearch CTO, @Lucidworks Exec. Focused on the intersection of Search & AI.

Andrey Pikunov @andrey_pikunov
0 Followers 7 Following

csehra @csehra42
62 Followers 183 Following AI Engineer | Building Production-Ready AI Infrastructure | System Design Specialist | Creating Scalable LLMOps Solutions
Nikolay Dandanov @NDandanov
7 Followers 325 Following
Pranesh @praneshbuilds
1K Followers 2K Following building the future of intelligence @ Ayma Superintelligence Interactive Corp {} everything you seek lies within you
吾唯知足 @_tt_09_17
7 Followers 513 Following
NeuronRun @neuron_run
49 Followers 414 Following Artificial intelligence, chatGPT, machine learning, technological singularity, technological evolution, human progress. https://t.co/BGcCIJEKvM
Pierre Tchedou @PTchedou
5 Followers 166 Following Data Engineer | Building reliable data pipelines and analytics solutions | Python • SQL • Airflow • Spark • AWS/GCP
Enid Lesch @LeschEnid6321
133 Followers 5K Following
Swieoogaw @Swieoogaw9964
60 Followers 3K Following
Archit Jain @architjain9j
7 Followers 156 Following Aspiring Remote Data Engineer | Snowflake, SQL, ETL, Python | Sharing projects & data insights
BRS @BrianSt23340891
12 Followers 306 Following

Goodnight @Mohammedarbi77
100 Followers 2K Following ML Nerd | @qdrant_engine Star | @Google DSC lead '23 Open to research & job opportunities

JB @jamie247
38K Followers 11K Following Chairman @oviohq, investing in The Post Web, supporting Digital Arts
Daniel Svonava @svonava
2K Followers 1K Following Inference for Sovereign Agents @superlinked | xYouTube Ads ML
Brendan Falk @BrendanFalk
10K Followers 2K Following Founder/CEO @ @UseHercules | Prev. Co-founder/CEO at @fig (acquired by @Amazon), @ycombinator @brexHQ @harvard | Australian 🇦🇺
Lark Cyphron @Cyphr0n
1K Followers 1K Following pfp by @FLUF_World banner by @dutchtide gallery: https://t.co/FWSqrNdMvO


Ryan Carson @ryancarson
184K Followers 16K Following Dad, Dev, CEO, 4x Founder. Building @HelloUntangle

Guangzheng Li @iguangzhengli
22K Followers 200 Following Blog📰: https://t.co/wcsjbz3ezH GitHub🚀: https://t.co/spQ6r1GWVa 独立开发者启动模板🛫: https://t.co/qVmbw0h5MY
Bryan Offutt @BryanOffutt
2K Followers 663 Following Co-founder/Partner @hanabicapital Prev Partner @IndexVentures, Infra Eng/PM@ Palantir + MemSQL
Karel Zheng @realKarelZheng
90 Followers 708 Following first ticket @BetterStackHQ, @e2b, @get_viktor_com, @topk_io, @riptidesio and others, Forbes 30u30, endurance athlete, math grad
Holly Peck @hollympeck
2K Followers 921 Following Something new. prev: ml infra @bytez • founding team/head of hri @thesanctuaryai • ml @ kindred (warehouse robots) • ai research + robotics
George Hotz 🌑 @realGeorgeHotz
304K Followers 204 Following President @comma_ai. Founder @__tinygrad__
Ben Gutkovich @bengutkovich
230 Followers 452 Following Co-Founder @Superlinked, ex-@mckinsey, ex-@Strategyand @LBS MBA, all opinions are mine; Cut model inference costs & scale reliably with https://t.co/6tzYlEsK0N

clem 🤗 @ClementDelangue
378K Followers 5K Following Co-founder & CEO @HuggingFace 🤗, the open and collaborative platform for AI builders
Philipp Schmid @_philschmid
86K Followers 1K Following Agents & Gemini API, MTS @GoogleDeepMind | prev: Tech Lead at @huggingface, AWS ML Hero 🤗 Sharing my own views and AI News 🧑🏻💻 https://t.co/7IosdlO6RA
John Nay @johnjnay
15K Followers 65 Following founder & CEO of Norm Ai // founding CEO of Brooklyn AI (acquired by TIAA Nuveen) // more at https://t.co/IpzZqFixUk
Jeremy Howard @jeremyphoward
315K Followers 7K Following 🇦🇺 Co-founder: @AnswerDotAI/@FastDotAI ; Prev: Professor@UQ; @kaggle founding president; founder @fastmail/@enlitic/… https://t.co/16UBFTX7mo
Big Data LDN - 23/24 ... @BigData_LDN
4K Followers 4K Following UK’s leading Data, AI & Analytics event - 23-24 September 2026. Two days of expert talks and hands-on solutions to build dynamic, data‑driven businesses.
Molly O’Shea @MollySOShea
61K Followers 870 Following Investing & Tech →Newsletter/Podcast @Sourceryy | HUGE Fan @brexhq @Turingcom @public @deel
Avinash @fullstackAvi
4K Followers 5K Following Principal Software Architect (Full-stack). Polyglot designer & dev. Big AI enthusiast. Blues lover. Full-time digital nomad. Hiker. Photog. Life-long learner.

DeepThinkTechnology @ThinkDeeperIoT
4 Followers 17 Following Dive Deeper. Emerging tech discussions, weekly posts, find what's new.

Abide A.I. @abideai
125 Followers 2 Following We are an AI research lab building the reasoning layer for AI agents.
Drew Shady | Automati... @ShadyDrew
1K Followers 5K Following I build automated systems to scale businesses helping them profit. Also home automation systems with latest tech! #AI | #Automation | #Systems | #Analytics
DataOlytics @DataOlytics
2K Followers 3K Following Data Over Analytics, Blockchain, DeFi, Dapps, Web3, (RWA - AI - Gaming - DePIN - DeSci - NFT), Quantum Computing, DATA centers, AI, Social Networks, Solutions.
Mr. Flow @HeyMrFlow
10 Followers 43 Following Delivering the latest AI news daily and strategies to elevate your digital IQ with top-tier AI insights
RECALL-CI @RECALL_CI
4 Followers 83 Following Future-craft fine jewellery designed to showcase CI* creative + collective intelligence. Ai x Human intelligence. Instagram : recallci
Tushar Babbar @TusharBabbar14
3 Followers 10 Following I'm a data science writer passionate about exploring and visualizing data to drive better decision-making. Join me on my journey of insights and analytics!
Chris Hernandez @Chernandez2023
19 Followers 23 Following Strategic leader designing & scaling ML solutions for quality orgs. Passionate about innovation, quality, and ML.
Aemon Algiz @AemonAlgizVids
42 Followers 17 Following Expert on Artificial Intelligence, Machine Learning, Large Language Models, and the future of computing.

Bhakti Nikam @BhaktiNikam
4 Followers 52 Following
NeuronRun @neuron_run
49 Followers 414 Following Artificial intelligence, chatGPT, machine learning, technological singularity, technological evolution, human progress. https://t.co/BGcCIJEKvM
Schmiff @Schmiffke
10 Followers 240 Following
Neo Harv @NeoHarv
1 Followers 12 Following
karan Choudhary @karanChoud62622
5 Followers 71 Following




Ana Bildea @AnaBildea
405 Followers 1K Following Tech Lead @Orange - 🎓 Ph.D. 💡 #AI, #Agents, #GenerativeAI, #SafetyAI #AGI #Production #LLMOPS ✍️ https://t.co/E5akKGOHJ1
Jay Alammar @JayAlammar
50K Followers 1K Following Machine Learning Researcher and writer https://t.co/5GlbofAHs0. O'Reilly Author https://t.co/Fl3uPAZHLg. LLM Builder @Cohere.
Omar Sanseviero @osanseviero
70K Followers 3K Following MTS at @GoogleDeepMind Building Gemini, Gemma, AI Studio and more. My views ex-Chief Llama Officer @huggingface 🇵🇪🇲🇽
merve @mervenoyann
88K Followers 5K Following (mer-veh) open-sourceress at @huggingface 🧙🏻♀️ DM me for any feedback about HF 🤗 https://t.co/MhrMkGTm7p
Jean de Dieu Nyandwi @Jeande_d
49K Followers 1K Following Incoming CS PhD @CarnegieMellon • Multimodal NLP, Data, Evals, Human + AI • CMU MS '24. Blog: https://t.co/1BEFLZAY3F ML: https://t.co/7PkTyDw2gQ
Mark Tenenholtz @marktenenholtz
150K Followers 702 Following Member of Technical Staff @perplexity_ai
AK @_akhaliq
504K Followers 3K Following AI research paper tweets, ML @Gradio (acq. by @HuggingFace 🤗) dm for promo ,submit papers here: https://t.co/UzmYN5XOCi
You might like













